Разделы
Счетчики
Популярно о генетических алгоритмах
Природа поражает своей сложностью и богатством всех своих проявлений. Среди примеров можно назвать сложные социальные системы, иммунные и нейронные системы, сложные взаимосвязи между видами. Они - всего лишь некоторые из чудес, которые стали более очевидны, когда мы стали глубже исследовать себя самих и мир вокруг нас. Наука - это одна из сменяющих друг друга систем веры, которыми мы пытается объяснять то, что наблюдаем, этим самым изменяя себя, чтобы приспособиться к новой информации, получаемой из внешнего мира. Многое из того, что мы видим и наблюдаем, можно объяснить единой теорией: теорией эволюции через наследственность, изменчивость и отбор.
Теория эволюции повлияла на изменение мировоззрения людей с самого своего появления. Теория, которую Чарльз Дарвин представил в работе, известной как "Происхождение Видов", в 1859 году, стала началом этого изменения. Многие области научного знания в настоящее время наслаждаются свободой мысли в атмосфере, которая многим обязана революции, вызванной теорией эволюции и развития. Но Дарвин, подобно многим своим современникам, кто предполагал, что в основе развития лежит естественный отбор, не мог не ошибаться. Например, он не смог показать механизм наследования, при котором поддерживается изменчивость. Его гипотеза о пангенезисе оказалась неправильной. Это было на пятьдесят лет до того, как теория наследственности начала распространяться по миру, и за тридцать лет до того, как "эволюционный синтез" укрепил связь между теорией эволюции и относительно молодой наукой генетикой. Однако Дарвин выявил главный механизм развития: отбор в сочетании с изменчивостью или, как он его называл, "спуск с модификацией". Во многих случаях, специфические особенности развития через изменчивость и отбор все еще не бесспорны, однако, основные механизмы объясняют невероятно широкий спектр явлений, наблюдаемых в Природе.
Поэтому неудивительно, что ученые, занимающиеся компьютерными исследованиями, обратились к теории эволюции в поисках вдохновения. Возможность того, что вычислительная система, наделенная простыми механизмами изменчивости и отбора, могла бы функционировать по аналогии с законами эволюции в природных системах, была очень привлекательна. Эта надежда стала причиной появления ряда вычислительных систем, построенных на принципах естественного отбора.
История эволюционных вычислений началась с разработки ряда различных независимых моделей. Основными из них были генетические алгоритмы и классификационные системы Голланда (Holland), опубликованные в начале 60-х годов и получившие всеобщее признание после выхода в свет книги, ставшей классикой в этой области ("Адаптация в естественных и искусственных системах", 1975). В 70-х годах в рамках теории случайного поиска Л.А.Растригиным был предложен ряд алгоритмов, использующих идей бионического поведения особей. Развитие этих идей нашло отражение в цикле работ И.Л.Букатовой по эволюционному моделированию. Развивая идеи М.Л.Цетлина о целесообразном и оптимальном поведении стохастических автоматов, Ю.И.Неймарк предложил осуществлять поиск глобального экстремума на основе коллектива независимых автоматов, моделирующих процессы развития и элиминации особей. Большой вклад в развитие эволюционного программирования внесли Фогел (Fogel) и Уолш (Walsh). Несмотря на разницу в подходах, каждая из этих "школ" взяла за основу ряд принципов, существующих в природе, и упростила их до такой степени, чтобы их можно было реализовать на компьютере.
Главная трудность с возможностью построения вычислительных систем, основанных на принципах естественного отбора, и применением этих систем в прикладных задачах состоит в том, что природные системы достаточно хаотичны, а все наши действия, фактически, носят четкую направленность. Мы используем компьютер как инструмент для решения определенных задач, которые мы сами и формулируем, и мы акцентируем внимание на максимально быстром выполнении при минимальных затратах. Природные системы не имеют никаких таких целей или ограничений, во всяком случае, нам они не очевидны. Выживание в природе не направлено к некоторой фиксированной цели, вместо этого эволюция совершает шаг вперед в любом доступном ей направлении.
Возможно это большое обобщение, но я полагаю, что усилия, направленные на моделирование эволюции по аналогии с природными системами, к настоящему времени можно разбить на две большие категории. Первая категория - это системы, которые смоделированы на биологических принципах. Они успешно использовались для задач типа функциональной оптимизации и могут легко быть описаны на небиологическом языке. Вторая категория - системы, которые являются биологически более реалистичными, но которые не оказались особенно полезными в прикладном смысле. Они больше похожи на биологические системы и менее направлены (или не направлены вовсе). Они обладают сложным и интересным поведением, и, видимо, вскоре получат практическое применение.
Конечно, на практике мы не можем разделять эти вещи так строго. Эти категории - просто два полюса, между которыми лежат различные вычислительные системы. Ближе к первому полюсу - эволюционные алгоритмы, такие как Эволюционное программирование, Генетические алгоритмы и Эволюционные стратегии. Ближе ко второму полюсу - системы, которые могут быть классифицированы как Искусственная жизнь.
Конечно, эволюция биологических систем не единственный "источник вдохновения" создателей новых методов, моделирующих природные процессы. Нейронные сети, например, основаны на моделировании поведения нейронов в мозге. Они могут использоваться для ряда задач классификации, например, задачи распознавания образов, машинного обучения, обработки изображений и другого. Область их приложения частично перекрывается со сферой применения генетических алгоритмов. Модельный отжиг - другая методика поиска, которая основана скорее на физических, а не биологических процессах.
Генетические алгоритмы
Генетические алгоритмы - адаптивные методы поиска, которые в последнее время часто используются для решения задач функциональной оптимизации. Они основаны на генетических процессах биологических организмов: биологические популяции развиваются в течении нескольких поколений, подчиняясь законам естественного отбора и по принципу "выживает наиболее приспособленный", открытому Чарльзом Дарвином. Подражая этому процессу генетические алгоритмы способны "развивать" решения реальных задач, если те соответствующим образом закодированы. Например, генетические алгоритмы могут использоваться, чтобы проектировать структуры моста, для поиска максимального отношения прочности/веса, или определять наименее расточительное размещение для нарезки форм из ткани. Они могут также использоваться для интерактивного управления процессом, например, на химическом заводе, или балансировании загрузки на многопроцессорном компьютере. Вполне реальный пример: израильская компания Schema разработала программный продукт Channeling для оптимизации работы сотовой связи путем выбора оптимальной частоты, на которой будет вестись разговор. В основе этого программного продукта и используются генетические алгоритмы.
Основные принципы генетических алгоритмов были сформулированы Голландом в 1975 году, и хорошо описаны во многих работах. В отличие от эволюции, происходящей в природе, генетические алгоритмы только моделируют те процессы в популяциях, которые являются существенными для развития. Точный ответ на вопрос, какие биологические процессы существенны для развития, и какие нет - все еще открыт для исследователей.
В природе особи в популяции конкурируют друг с другом за различные ресурсы, такие, например, как пища или вода. Кроме того, члены популяции одного вида часто конкурируют за привлечение брачного партнера. Те особи, которые наиболее приспособлены к окружающим условиям, будут иметь относительно больше шансов воспроизвести потомков. Слабо приспособленные особи либо совсем не произведут потомства, либо их потомство будет очень немногочисленным. Это означает, что гены от высоко адаптированных или приспособленных особей будут распространяться в увеличивающемся количестве потомков на каждом последующем поколении. Комбинация хороших характеристик от различных родителей иногда может приводить к появлению "супер приспособленного" потомка, чья приспособленность больше, чем приспособленность любого из его родителя. Таким образом, вид развивается, лучше и лучше приспосабливаясь к среде обитания.
Генетические алгоритмы используют прямую аналогию с таким механизмом. Они работают с совокупностью "особей" - популяцией, каждая из которых представляет возможное решение данной проблемы. Каждая особь оценивается мерой ее "приспособленности" согласно тому, насколько "хорошо" соответствующее ей решение задачи. Например, мерой приспособленности могло бы быть отношение силы/веса для данного проекта моста (в природе это эквивалентно оценке того, насколько эффективен организм при конкуренции за ресурсы). Наиболее приспособленные особи получают возможность "воспроизводить" потомство с помощью "перекрестного скрещивания" с другими особями популяции. Это приводит к появлению новых особей, которые сочетают в себе некоторые характеристики, наследуемые ими от родителей. Наименее приспособленные особи с меньшей вероятностью смогут воспроизвести потомков, так что те свойства, которыми они обладали, будут постепенно исчезать из популяции в процессе эволюции.
Так и воспроизводится вся новая популяция допустимых решений, выбирая лучших представителей предыдущего поколения, скрещивая их и получая множество новых особей. Это новое поколение содержит более высокое соотношение характеристик, которыми обладают хорошие члены предыдущего поколения. Таким образом, из поколения в поколение, хорошие характеристики распространяются по всей популяции. Скрещивание наиболее приспособленных особей приводит к тому, что исследуются наиболее перспективные участки пространства поиска. В конечном итоге, популяция будет сходиться к оптимальному решению задачи.
Имеются много способов реализации идеи биологической эволюции в рамках генетических алгоритмов. Традиционным считается генетический алгоритм, представленный на схеме.
Создать начальную популяцию
Оценить приспособленность каждой особи
останов := FALSE
ЦИКЛ ПОКА останов = False
ЦИКЛ (размер_популяции / 2) РАЗ
1) Выбрать две особи с высокой приспособленностью
из предыдущего поколения для скрещивания
2) Скрестить выбранные особи и получить
двух потомков
3) Оценить приспособленности потомков
4) Поместить потомков в новое поколение
КОНЕЦ ЦИКЛА
ЕСЛИ популяция сошлась ТО останов := TRUE
КОНЕЦ ЦИКЛАВ последние годы реализовано много генетических алгоритмов и в большинстве случаев они мало похожи на этот генетический алгоритм. По этой причине в настоящее время под термином "генетические алгоритмы" скрывается не одна модель, а достаточно широкий класс алгоритмов, подчас мало похожих друг на друга. Исследователи экспериментировали с различными типами представлений, операторов скрещивания и мутации, специальных операторов, и различных подходов к воспроизводству и отбору.
Хотя модель эволюционного развития, применяемая в генетических алгоритмах, сильно упрощена по сравнению со своим природным аналогом, тем не менее, генетический алгоритм является достаточно мощным средством и может с успехом применяться для широкого класса прикладных задач, включая те, которые трудно, а иногда и вовсе невозможно, решить другими методами. Однако, генетический алгоритм, как и другие методы эволюционных вычислений, не гарантирует обнаружения глобального решения за полиномиальное время. Генетические алгоритмы не гарантируют и того, что глобальное решение будет найдено, но они хороши для поиска "достаточно хорошего" решения задачи "достаточно быстро". Там, где задача может быть решена специальными методам, почти всегда такие методы будут эффективнее генетических алгоритмов и в быстродействии, и в точности найденных решений. Главным же преимуществом генетических алгоритмов является то, что они могут применяться даже на сложных задачах, там, где не существует никаких специальных методов. Даже там, где хорошо работаю существующие методики, можно достигнуть улучшения сочетанием их с генетическими алгоритмами.
Когда следует применять генетический алгоритм?
Генетические алгоритмы в различных формах применялись ко многим научным и техническим проблемам. Генетические алгоритмы использовались при создании других вычислительных структур, например, автоматов или сетей сортировки. В машинном обучении они использовались при проектировании нейронных сетей или управлении роботами. Они также применялись при моделировании развития в различных предметных областях, включая биологические (экология, иммунология и популяционная генетика), социальные (такие как экономика и политические системы) и когнитивные системы.
Тем не менее, возможно наиболее популярное приложение генетических алгоритмов - оптимизация многопараметрических функций. Многие реальные задачи могут быть сформулированы как поиск оптимального значения, где значение - сложная функция, зависящая от некоторых входных параметров. В некоторых случаях представляет интерес найти те значения параметров, при которых достигается наилучшее точное значение функции. В других случаях точный оптимум не требуется - решением может считаться любое значение, которое лучше некоторой заданной величины. В этом случае генетические алгоритмы - часто наиболее приемлемый метод для поиска "хороших" значений. Сила генетического алгоритма заключена в его способности манипулировать одновременно многими параметрами. Эта особенность генетических алгоритмов использовалась в сотнях прикладных программ, включая проектирование самолетов, настройку параметров алгоритмов и поиск устойчивых состояний систем нелинейных дифференциальных уравнений.
Однако нередки случаи, когда генетический алгоритм работает не так эффективно, как ожидалось. Предположим, есть реальная задача, сопряженная с поиском оптимального решения. Как узнать, является ли генетический алгоритм хорошим методом для ее решения? До настоящего времени не существует строгого ответа, однако многие исследователи разделяют предположения, что если пространство поиска, которое предстоит исследовать, достаточно большое, и предполагается, что оно не совершенно гладкое и унимодальное (то есть содержит один гладкий экстремум) или не очень понятно, или если функция приспособленности с шумами, или если задача не требует строго нахождения глобального оптимума - то есть если достаточно быстро просто найти приемлемое "хорошее" решения (что довольно часто имеет место в реальных задачах) - генетический алгоритм будет иметь хорошие шансы стать эффективной процедурой поиска, конкурируя и превосходя другие методы, которые не используют знания о пространстве поиска.
Если же пространство поиска небольшое, то решение может быть найдено методом полного перебора, и можно быть уверенным, что наилучшее возможное решение найдено, тогда как генетический алгоритм мог с большей вероятностью сойтись к локальному оптимуму, а не к глобально лучшему решению. Если пространство гладкое и унимодальное, тогда любой градиентный алгоритм, такой как метод скорейшего спуска, будет более эффективен, чем генетический алгоритм. Если о пространстве поиска есть некоторая дополнительная информация (как, например, пространство для хорошо известной задачи о коммивояжере), методы поиска, использующие эвристики, определяемые пространством, часто превосходят любой универсальный метод, каким является генетический алгоритм. При достаточно сложном рельефе функции приспособленности, методы поиска с единственным решением в каждый момент времени, такие как простой метод спуска, могли "затыкаться" в локальном решении, однако считается, что генетические алгоритмы, так как они работают с целой "популяцией" решений, имеют меньше шансов сойтись к локальному оптимуму и робастно функционируют на многоэкстремальном ландшафте.
Конечно, такие предположения не предсказывают строго, когда генетический алгоритм будет эффективной процедурой поиска, конкурирующей с другими процедурами. Эффективность генетического алгоритма сильно зависит от таких деталей, как метод кодировки решений, операторы, настройки параметров, частный критерий успеха. Теоретическая работа, отраженная в литературе, посвященной генетическим алгоритмам, не дает оснований говорить о выработки каких-либо строгих механизмов для четких предсказаний.
Символьная модель простого генетического алгоритма
Цель в оптимизации с помощью генетического алгоритма состоит в том, чтобы найти лучшее возможное решение или решения задачи по одному или нескольким критериям. Чтобы реализовать генетический алгоритм, нужно сначала выбрать подходящую структуру для представления этих решений. В постановке задачи поиска экземпляр этой структуры данных представляет точку в пространстве поиска всех возможных решений.
Структура данных генетического алгоритма состоит из одной или большего количества хромосом (обычно из одной). Как правило, хромосома - это битовая строка, так что термин "строка" часто заменяет понятие "хромосома". В принципе, генетические алгоритмы не ограничены бинарным представлением. Известны другие реализации, построенные исключительно на векторах вещественных чисел. Несмотря на то, что для многих реальных задач, видимо, больше подходят строки переменной длины, в настоящее время структуры фиксированной длины наиболее распространены и изучены. Пока и мы ограничимся только структурам, которые являются одиночными строками по L бит.
Каждая хромосома (строка) представляет собой конкатенацию ряда субкомпонентов, называемых генами. Гены располагаются в различных позициях или локусах хромосомы, и принимают значения, называемые аллелями. В представлениях с бинарными строками, ген - бит, локус - его позиция в строке, и аллель - его значение (0 или 1). Биологический термин "генотип" относится к полной генетической модели особи и соответствует структуре в генетическом алгоритме. Термин "фенотип" относится к внешним наблюдаемым признакам и соответствует вектору в пространстве параметров. Чрезвычайно простой, но иллюстративный пример - задача максимизации следующей функции двух переменных:
f (x1, x2) = exp(x1 x2), где 0 < x1 < 1 и 0 < x2 < 1
Обычно методика кодирования реальных переменных x1 и x2 состоит в их преобразовании в двоичные целочисленные строки достаточной длины - достаточной для того, чтобы обеспечить желаемую точность. Предположим, что 10-разрядное кодирование достаточно и для x1, и для x2. Установить соответствие между генотипом и фенотипом закодированных особей можно, разделив соответствующее двоичное целое число на 2^10-1. Например, 0000000000 соответствует 0/1023 или 0, тогда как 1111111111 соответствует 1023/1023 или 1. Оптимизируемая структура данных - 20-битная строка, представляющая конкатенацию кодировок x1 и x2. Переменная x1 размещается в крайних левых 10-разрядах, тогда как x2 размещается в правой части генотипа особи (20-битовой строке). Генотип - точка в 20-мерном хеммининговом пространстве, исследуемом генетическим алгоритмом. Фенотип - точка в двумерном пространстве параметров.
Чтобы оптимизировать структуру, используя генетический алгоритм, нужно задать некоторую меру качества для каждой структуры в пространстве поиска. Для этой цели используется функция приспособленности. В функциональной максимизации целевая функция часто сама выступает в качестве функции приспособленности (например, наш двумерный пример); для задач минимизации целевую функцию следует инвертировать и сместить затем в область положительных значений.
Работа простого генетического алгоритма
Простой генетический алгоритм случайным образом генерирует начальную популяцию структур. Работа генетического алгоритма представляет собой итерационный процесс, который продолжается до тех пор, пока не выполнятся заданное число поколений или какой-либо иной критерий остановки. На каждом поколении генетическим алгоритмом реализуется отбор пропорционально приспособленности, одноточечное скрещивание и мутация. Сначала пропорциональный отбор назначает каждой структуре вероятность Ps(i), равную отношению ее приспособленности к суммарной приспособленности популяции:
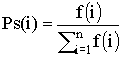
Затем происходит отбор (с замещением) всех N особей для дальнейшей генетической обработки, согласно величине Ps(i). Простейший пропорциональный отбор - рулетка - отбирает особей с помощью N "запусков" рулетки. Колесо рулетки содержит по одному сектору для каждого члена популяции. Размер i-ого сектора пропорционален соответствующей величине Ps(i). При таком отборе члены популяции с более высокой приспособленностью с большей вероятность будут чаще выбираться, чем особи с низкой приспособленностью.
После отбора N выбранных особей подвергаются скрещиванию (иногда называемому рекомбинацией) с заданной вероятностью Pc. N строк случайным образом разбиваются на N/2 пары. Для каждой пары с вероятность Pc может применяться скрещивание. Соответственно с вероятностью 1-Pc скрещивание не происходит, и неизмененные особи переходят на стадию мутации. Если скрещивание происходит, полученные потомки заменяют собой родителей и переходят к мутации.
Одноточечное скрещивание работает следующим образом. Сначала случайным образом выбирается одна из L-1 точек разрыва (точка разрыва - участок между соседними битами в строке). Обе родительские структуры разрываются на два сегмента по этой точке. Затем соответствующие сегменты различных родителей склеиваются и получаются два генотипа потомков.
Например, предположим, один родитель состоит из 10 нулей, а другой - из 10 единиц. Пусть из 9 возможных точек разрыва выбрана точка 3. Родители и их потомки показаны ниже.
Скрещивание
Родитель 1 --> 0000000000 --> 1110000000 --> Потомок 1
000~0000000 111~0000000
Родитель 2 --> 1111111111 --> 0001111111 --> Потомок 2
111~1111111 000~1111111После того как закончится стадия скрещивания, выполняются операторы мутации. В каждой строке, которая подвергается мутации, каждый бит с вероятностью Pm изменяется на противоположный. Популяция, полученная после мутации, записывает поверх старой и этим цикл одного поколения завершается. Последующие поколения обрабатываются таким же образом: отбор, скрещивание и мутация.
В настоящее время исследователи генетических алгоритмов предлагают много других операторов отбора, скрещивания и мутации. Вот лишь наиболее распространенные из них. Прежде всего, турнирный отбор. Турнирный отбор реализует N турниров, чтобы выбрать N особей. Каждый турнир построен на выборке K элементов из популяции, и выбора лучшей особи среди них. Наиболее распространен турнирный отбор с K=2.
Элитные методы отбора гарантируют, что при отборе обязательно будут выживать лучший или лучшие члены популяции в совокупности. Наиболее распространена процедура обязательного сохранения только одной лучшей особи, если она не прошла, как другие, через процесс отбора, скрещивания и мутации. Элитизм может быть внедрен практически в любой стандартный метод отбора.
Двухточечное скрещивание и равномерное скрещивание - вполне достойные альтернативы одноточечному оператору. В двухточечном скрещивании выбираются две точки разрыва, и родительские хромосомы обмениваются сегментом, который находится между двумя этими точками. В равномерном скрещивании каждый бит первого родителя наследуется первым потомком с заданной вероятностью; в противном случае этот бит передается второму потомку. И наоборот.
Шима (schema)
Хотя внешне кажется, что генетический алгоритм обрабатывает строки, на самом деле при этом неявно происходит обработка шим, которые представляют шаблоны подобия между строками. Генетический алгоритм практически не может заниматься полным перебором всех точек в пространстве поиска. Однако он может производить выборку значительного числа гиперплоскостей в областях поиска с высокой приспособленностью. Каждая такая гиперплоскость соответствует множеству похожих строк с высокой приспособленностью.
Шима - это строка длины L (что и длина любой строки популяции), состоящая из знаков алфавита (0, 1, *), где (*) - неопределенный символ. Каждая шима определяет множество всех бинарных строк длины L, имеющих в соответствующих позициях либо 0, либо 1, в зависимости от того, какой бит находится в соответствующей позиции самой шимы. Например, шима 10**1 определяет собой множество из четырех пятибитовых строк (10001, 10011, 10101, 10111). У шим выделяют два свойства - порядок и определенная длина. Порядок шимы - это число определенных битов (0 или 1) в шиме. Определенная длина - расстояние между крайними определенными битами в шиме. Например, вышеупомянутая шима имеет порядок O(10**1) = 3, а определенная длина б(10**1) = 4. Каждая строка в популяции является примером 2^L шим.
Строящие блоки
Строящие блоки - это шимы обладающие:
1) высокой приспособленностью 2) низким порядком 3) короткой определенной длиной
Приспособленность шимы определяется как среднее приспособленностей примеров, которые ее содержат. После процедуры отбора остаются только строки с более высокой приспособленностью. Следовательно, строки, которые являются примерами шим с высокой приспособленностью, выбираются чаще. Скрещивание реже разрушает шимы с более короткой определенной длиной, а мутация реже разрушает шимы с низким порядком. Поэтому такие шимы имеют больше шансов переходить из поколения в поколение. Голланд показал, что в то время как генетический алгоритм явным образом обрабатывает N строк на каждом поколении, в тоже время неявно обрабатываются порядка N^3 таких коротких шим низкого порядка и с высокой приспособленностью (полезных шим). Он называл это явление неявным параллелизмом. Для решения реальных задач присутствие неявного параллелизма означает, что большая популяция имеет больше возможностей локализовать решение экспоненциально быстрее популяции с меньшим числом особей.
Теорема шим
Простой генетический алгоритм экспоненциально увеличивает число примеров полезных шим или строящих блоков. Доказательством этого служит следующая теорема, известная как "теорема шим".
Пусть m(H,t) - число примеров шимы H в t-ом поколении. Вычислим ожидаемое число примеров H в следующем поколении или m(H,t+1) в терминах m(H,t). Простой генетический алгоритм каждой строке ставит в соответствие вероятность ее "выживания" при отборе пропорционально ее приспособленности. Ожидается, что шима H может быть выбрана m(H,t)*(f(H)/fср) раз, где fср - средняя приспособленность популяции, а f(H) - средняя приспособленность тех строк в популяции, которые являются примерами H.
Вероятность того, что одноточечное скрещивание разрушит шиму, равна вероятности того, что точка разрыва попадет между определенными битами. Вероятность же того, что H "переживает" скрещивание не меньше 1-Pc*(б(H)/L-1). Эта вероятность - неравенство, поскольку шима сможет выжить, если в скрещивании участвовал также пример похожей шимы. Вероятность того, что H переживет мутацию - (1-Pm)^O(H), это выражение можно аппроксимировать как (1-O(H)) для малого Pm и O(H). Произведение ожидаемого числа отборов и вероятностей выживания известно как теорема шим:
m (H, t+1) 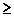
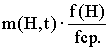
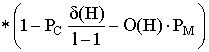
Теорема шим показывает, что строящие блоки растут по экспоненте, в то время шимы с приспособленностью ниже средней распадаются с той же скоростью. Goldberg в своих исследованиях теоремы шим выдвигает гипотезу строящих блоков, которая состоит в том, что "строящие блоки объединяются, чтобы сформировать лучшие строки". То есть рекомбинация и экспоненциальный рост строящих блоков ведет к формированию лучших строящих блоков.
В то время как теорема шим предсказывает рост примеров хороших шим, сама теорема весьма упрощенно описывает поведение генетического алгоритма. Прежде всего, f(H) и fср не остаются постоянными от поколения к поколению. Приспособленности членов популяции знаменательно изменяются уже после нескольких первых поколений. Во-вторых, теорема шим объясняет потери шим, но не появление новых. Новые шимы часто создаются скрещиванием и мутацией. Кроме того, по мере эволюции члены популяции становятся все более и более похожими друг на друга, так что разрушенные шимы будут сразу же восстановлены. Наконец, доказательство теоремы шим построено на элементах теории вероятности и, следовательно, не учитывает разброс значений. Во многих интересных задачах разброс значений приспособленности шимы может быть достаточно велик, делая процесс формирования шим очень сложным. Существенная разница приспособленности шимы может привести к сходимости к неоптимальному решению.
Несмотря на простоту, теорема шим описывает несколько важных аспектов поведения генетического алгоритма. Мутации с большей вероятностью разрушают шимы высокого порядка, в то время как скрещивания с большей вероятность разрушают шимы с большей определенной длиной. Когда происходит отбор, популяция сходится пропорционально отношению приспособленности лучшей особи к средней приспособленности в популяции; это отношение - мера давления отбора. Увеличение или Pc, или Pм, или уменьшение давления отбора ведет к увеличенному осуществлению выборки или исследованию пространства поиска, но не позволяет использовать все хорошие шимы, которыми располагает генетический алгоритм. Уменьшение или Pc, или Pм, или увеличение давления выбора ведет к улучшению использования найденных шим, но тормозит исследование пространства в поисках новых хороших шим. Генетический алгоритм должен поддержать тонкое равновесие между тем и другим, что обычно известно как проблема "баланса исследования и использования".
Некоторые исследователи критиковали обычно быструю сходимость генетического алгоритма, заявляя, что испытание огромных количеств перекрывающихся шим требует большей выборки и более медленной, более управляемой сходимости. В то время как увеличить выборку шим можно, увеличив размер популяции, методология управления сходимостью простого генетического алгоритма до сих пор не выработана.
Сергей Исаев, 17 мая 2003 года