Разделы
Счетчики
Секреты закона распределения простых чисел
Излагаемый далее материал будет полезен как исследователям теории простых чисел, желающим ознакомиться со свежими изысканиями в этой области, в частности касаемо уточнений закона распределения простых чисел, так и просто интересующимся этой темой читателям, ведь само изложение для понимания не требует очень уж глубоких знаний в теории чисел и каждое сложное место доступно разъясняется. Речь в принципе пойдет о некоторых нюансах закона и какие размышления к ним приводят, основной же целью разговора станет путь к наипростейшим в смысле вычислительных затрат методам расчета приближенно точного количества простых чисел.
Краткая история возникновения закона
Исторически первыми к проблемам простых чисел - этим термином называют натуральные (целые положительные) числа, которые имеют всего два натуральных делителя, то есть делятся без остатка только на единицу и самих себя, - притронулись древние математики. В то время они могли построить довольно-таки обширные таблицы простых чисел, на что математикам прошлого требовались, вне всякого сомнения, годы трудоемких вычислений, но закономерность количества простых чисел перед каким-либо произвольно заданным числом усмотреть оказывалось невозможным в силу отсутствия должных математических операций.
Со временем в математику вошло понятие логарифма, и только более чем сотню лет спустя после этого события французскому математику Адриену Мари Лежандру и немецкому ученому Карлу Фридриху Гауссу независимо друг от друга удалось высказать гипотезу о том, что величина ¶(n) - так в теории чисел обозначают количество простых чисел, не превосходящих натуральное число n, - может быть приближенно выражена следующим отношением:
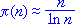
Прежде всего уточним, почему математики решили, что заданное число нужно делить на его натуральный логарифм для получения количества предшествующих ему простых чисел. Если построить небольшую таблицу, в которой число n увеличивается с каждым шагом в 10 раз, а также рядом к каждому n записать количество не превышающих его простых чисел, а еще правее отношение n к этому количеству, то обращает на себя внимание факт возрастания чисел в последнем столбце таблицы примерно на 2,3 (особенно это заметно начиная с третьей строки).
Натуральный логарифм числа 10 (а в это число раз увеличивалось с каждым шагом n) как раз оказывался близок к примерному возрастанию чисел последнего столбца. То есть ln 10=2,3025... - и вполне резонно было предположить, что количество простых чисел, предшествующих числу n, - это отношение числа n к его натуральному логарифму.
Вот так и появилась известная ныне формула. Но поскольку она все же давала (предсказывала) приблизительные результаты, ее назвали записью асимптотического (то есть не истинно точного) закона распределения простых чисел. Погрешность предсказания результата у такой записи можно оценить по следующей таблице, где в предпоследней колонке указано предсказываемое записью количество простых чисел, а в последней колонке - расхождение с реальным их количеством.
Для n=10 миллиардов предсказание расходится уже не менее чем на 20 миллионов простых чисел, и чем дальше двигаться по ряду натуральных чисел, тем оно сильнее и сильнее расходится, но ближе к бесконечности снова начинает улучшаться (почему, поймете далее). Проще говоря, предложенное выражение явно занижало количество простых чисел при продвижении по ряду чисел. Требовалось сделать какое-то более точное приближение, уточнить запись асимптотического закона распределения простых чисел. Причем крайне важно было, чтобы запись по-прежнему оставалась такой же простой.
Как уточняли закон
Зададимся вроде бы нелепым вопросом: зачем нужно искать наилучшее приближение, да еще чтобы оно записывалось элементарной формулой? Простые числа как объект исследования чрезвычайно сложен, поэтому математики на первых порах рады даже асимптотическому закону. Но человеку свойственно желать большего, хотеть постигнуть основу непонятного явления, причем выразить ее наиболее простой аналитической записью. Во-первых, чтобы суть явления не скрывалась за ворохом математических операций, прямо не относящихся к нему, а часто вообще выступающих введенными на время эмпирическими (опытными) поправками. Так сказать, всегда есть желание видеть функциональную связь в чистом виде, то есть какие действительные начала определяют в конечном счете наблюдаемый итог. Во-вторых, незамысловатая запись как помогает просто в вычислениях, особенно выполняемых на скорую руку, так и способствует процветанию новых идейных соображений, ведь в случае огрубленных формулировок гораздо легче сопоставлять с фактическими сведениями особенности поведения какой-либо упрощенной и удобопонятной функции, и уже, отталкиваясь от результатов сравнения, более рационально вводить в нее корректирующие коэффициенты или математические операции.
Собственно, похожим образом дело продвигалось и с законом распределения простых чисел. Его первичная запись пусть и была далека от идеала, зато изучение предложенного отношения, например его графического представления, не составляет особого труда и дает несравненно больше наводок о том, как лучше искать приближение к истине. Скажем, следующий рисунок прекрасно иллюстрирует пользу от наличия хотя бы какой-то примерной функциональной зависимости. Легко видеть и общую картину расхождения, и возможные пути его устранения. В данном случае кривая формулы асимптотического закона распределения простых чисел в целом походит на кривую действительного их количества, и если бы удалось подобрать какой-то корректирующий коэффициент, поворачивающий кривую на малый угол, чтобы она налегла на эталонную кривую, задача была бы решена значительно точнее. Впрочем, серьезное разбирательство выявляет, что здесь, строго говоря, приходится иметь дело с весьма специфичными кривыми, и банальным поворотом одной из них трудности устраняются лишь для малого участка числового ряда.
Итак, вернемся к истории уточнения закона. Поначалу математиками была высказана здравая гипотеза: делить n нужно не на ln n, а на ln n - 1 (не спутайте: единица вычитается из логарифма, а не из числа n). Однако к 1809 году Лежандр провел более точные вычисления на числах до миллиона и пришел к заключению, что еще точнее оказывается деление на ln n - 1,08366. То есть запись асимптотического закона распределения простых чисел принимала теперь усовершенствованный вид:

Вот эта поправка как раз и являла собой пример удачного приближения, повышения точности за счет "поворота" кривой на графике, а если говорить строже, за счет масштабирования в сторону понижения аргумента натурального логарифма (фактически в знаменателе нового отношения вычислялся логарифм выражения n/e1,08366) или, по-иному, за счет смещения логарифмики (так именуют кривую логарифмической функции) вниз на 1,08366 по координатной сетке, отчего кривая всего отношения как бы поворачивалась.
Сейчас следует сразу ответить на принципиальный вопрос: почему математики не повернули кривую на нужный угол обычным образом, то есть вокруг начала координат с помощью тригонометрических функций? Дело в том, что если построить сравнительный график логарифмики знаменателя асимптотического закона и "логарифмики" n/¶(n) в диапазоне чисел от нуля до бесконечности, то с очевидностью проявится своенравный характер последней кривой, нестатичность основания ее логарифма, словно бы основание от некоторого значения в начале ряда чисел плавно приближается (вообще картина этого приближения очень напоминает поведение функции y=x√x) в бесконечности к константе e - основанию натурального логарифма. Следующий рисунок наглядно показывает отличие логарифмик со статичными основаниями (для усиления представления серым цветом изображены логарифмики с некоторыми другими неизменными основаниями) и нестатичным для выражения n/¶(n).
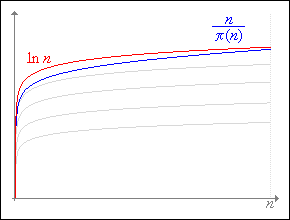
Данный рисунок позволяет понять, почему к бесконечности показания асимптотического закона распределения простых чисел снова начинают улучшаться, быть более точными к истине. Кроме того, по рисунку ясно, почему не годится поворот кривой в традиционном понимании, то есть вокруг начала координат. Также повышается понимание введенной Лежандром поправки. В этом случае логарифмика ln n просто смещалась вниз на 1,08366.
Другое дело, что возникал новый вопрос: что это за коэффициент такой (или же что это за число e1,08366), какова собственная функциональная зависимость коэффициента? Ведь логарифмика всего лишь сместилась целиком, но не "разогнулась" подобно эталонной, и поэтому с указанной поправкой ситуация касаемо предсказаний улучшалась лишь отчасти, всего-то для небольшого участка ряда чисел, за ним опять уходя в критичное расхождение. Для демонстрации этого снова построим прежнюю таблицу с истинным и ожидаемым количествами простых чисел и разницей между ними.
Как видно, расхождений уже меньше, но все-таки они и в этом случае достаточно велики, все сильнее возрастая по мере продвижения по ряду чисел. Так, например, для n=10 миллиардов предсказание завышается более чем на полмиллиона простых чисел.
В конце концов исследования русского математика Пафнутия Львовича Чебышева, человека, умевшего элементарными средствами находить фундаментальные результаты, в середине 19 века выявили, что если записать уточнение Лежандра в виде ln n - a, то с увеличением числа n до бесконечности коэффициент a должен постепенно уменьшаться до единицы, "разгибая" тем самым логарифмику до нужной формы (ведь ее начало тогда смещается вниз на большую величину, чем конец, который смещается только на единицу). То есть коэффициент Лежандра совсем не является константой, а некоторой неизвестной функцией f(n). Таким образом, невольно напрашивался вывод: запись асимптотического закона распределения простых чисел все же ближе именно к равенству
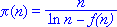
Нельзя сказать, что математики не пытались разгадать, что это за функция такая, просто никто, во-первых, не предполагал возможность ее простой записи, а во-вторых, негоже было гадать на кофейной гуще. К тому же развивались и другие подходы к уточнению закона. Скажем, в истории его уточнения было и хорошее приближение Гаусса интегральной суммой Ls(n) (или, взамен ей точнее, интегральным логарифмом Li(n)):
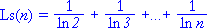
Существовало и приближение немецкого математика Бернхарда Римана функцией R(n), кстати которое оказывалось одним из самых точнейших, где расхождения колеблются в пределах тысячи простых чисел. Но здесь все эти приближения рассматривать не станем по простой причине (помимо сложного изложения их сущности): они требуют недюжинных вычислительных ресурсов. Скажем, просчет той же интегральной суммы для большого числа n потребует впечатляющего количества математических действий. В то время как уточнение Лежандра для какого угодно числа выполняется всегда в три приема: вычисляем натуральный логарифм заданного числа, вычитаем поправку 1,08366, делим заданное число на результат второго действия.
Интересующимся вопросами ручных вычислений перечислим порядок действий при расчете количества простых чисел по формуле Лежандра, скажем, для переключенного в инженерный режим калькулятора операционной системы Windows (жирным обозначены наименования кнопок, курсивом - комментарии):
вводим заданное число ln - вводим число 1,08366 = ...на экране финальное значение знаменателя / вводим заданное число = 1/x ... на экране предсказываемое количество простых чисел
А вот как выглядит исходный код (на языке Pascal) вычисления формулы Лежандра на компьютере. Вызываемая функция PrimeCount получает на входе заданное число N (ради обеспечения широкого диапазона чисел использован тип переменной Extended - число с плавающей запятой расширенной точности), а на выходе возвращает предсказываемое уточнением Лежандра количество простых чисел, предшествующих числу N.
function PrimeCount(N: extended): extended; begin // делаем заданное число целым и положительным // abs(a) - это взять модуль A // int(a) - это взять целую часть A N := abs(int(N)); // для чисел N=0 и N=1 расчет не имеет смысла // exit - это выйти из функции // Result - это переменная для обращения к // возвращаемому функцией значению Result := 0; if N < 2 then exit; // иначе вычисляем по формуле Лежандра // ln(a) - это вычислить натуральный логарифм A Result := N / (ln(N) - 1.08366); end;
Новые сведения
Понятно, что уточнение Лежандра привлекает в первую очередь простотой вычислений. Любой человек с инженерным калькулятором в руках справится с задачей в считанные секунды даже для очень громадных n. Хотелось бы, конечно, иметь наряду с этим аналогичную приближению Римана точность предсказаний, ну или хотя бы близкую к ней, сопоставимую по порядку точности. Да только для человека с калькулятором такая мечта выглядит призрачной. Однако кое-что придумать возможно, причем с сохранением простоты вычислений: всего потребуется 6 действий.
Вернемся на время к первой таблице. Обратим внимание, что, кроме возрастания чисел в последнем столбце таблицы приблизительно на величину натурального логарифма 10, они также примерно равны удвоенному показателю степени числа n по основанию 10.
Это наблюдение дает повод предположить, что кривая функции ¶(n) лежит между кривой упоминавшегося ранее отношения n/ln n (которое есть в оригинале ln en/ln n1) и кривой отношения ln 10n/ln n2=(n·ln 10)/(2·ln n), которое проще можно выразить как n/(2·lg n), что в оригинале есть lg 10n/lg n2. Следующий рисунок иллюстрирует сказанное.
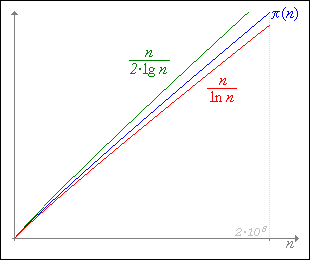
Можно было бы кривую, пролегающую посередине между крайними кривыми, принять в качестве приближения, только оно будет далеко не точным, поскольку синяя кривая в действительности все сильнее отклоняется в сторону красной кривой при устремлении n в бесконечность. Гораздо ближе к функции ¶(n) окажется следующее "усреднение" двух крайних кривых, опирающееся на чебышевское понимание уточнения Лежандра: корректирующий коэффициент есть функция. Так вот в обеих формулах крайних кривых мы видим, что число n делится на логарифмы этого же числа, только по разным основаниям. Перемножая выражения крайних кривых, в знаменателе получим 2·lg n·ln n, что можно записать как 2·ln 10·lg2n. Отбросим теперь множитель 2·ln 10, а квадрат десятичного логарифма числа используем как аргумент той самой корректирующей функции f(n), причем функция эта, на основе опытом установленного факта родства ее формы с формой уже известной нам функции y=x√x, будет именно такой. То есть воспользуемся следующим приближением:
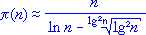
Как видно, здесь логарифмика уже будет "разгибаться" в нужном направлении, а не просто смещаться целиком. Обратимся за сведениями к соответствующей таблице.
Точность предсказаний возросла как минимум на порядок, сложность вычислений при этом осталась малой: 1) вычисляем десятичный логарифм заданного числа, 2) возводим результат в квадрат, 3) извлекаем из итога корень его же (итога) степени, 4) вычисляем натуральный логарифм заданного числа, 5) вычитаем полученное в предыдущем действии значение, 6) делим заданное число на результат последнего шага.
И на всякий случай перечислим порядок действий для калькулятора операционной системы Windows:
вводим заданное число log x^2 ...на экране квадрат десятичного логарифма числа установить флажок Inv x^y = MS (то есть сохраняем в памяти) ...на экране требуемый корень вводим заданное число ln - MR (то есть извлекаем из памяти) = ...на экране финальное значение знаменателя / вводим заданное число = 1/x ... на экране предсказываемое количество простых чисел
А также приведем исходный код для вычисления на компьютере (здесь дадим функции имя NewPrimeCount):
function NewPrimeCount(N: extended): extended; begin // делаем заданное число целым и положительным N := abs(int(N)); // для чисел N=0 и N=1 расчет не имеет смысла Result := 0; if N < 2 then exit; // иначе вычисляем по новой формуле // log10(a) - это вычислить десятичный логарифм A // power(a, b) - это возведение A в степень B (чтобы // использовать power, нужно подключить // в секцию uses модуль Math) // power(a, 1/b) - это извлечение корня B-ой степени из A Result := power(log10(N), 2); Result := power(Result, 1/Result); Result := N / (ln(N) - Result); end;
Все-таки хотелось бы иметь большую точность. Во всяком случае простота вычислений последнего уточнения устраивает. Но в чем же причина, что при вполне верном пути мысли к идее "разгибания" логарифмики она все же оказалась "недоразогнутой". Очевидно, возвращаясь к предыдущему графику, синяя кривая отклоняется к красной кривой несколько иначе, как раз так, что показатель степени аргумента функции f(n) тоже не статичен, и к бесконечности очень медленно понижается. То есть аргумент функции имеет вид lg2-xn, где x - вероятно, тоже подчинен какой-то функциональной зависимости. Впрочем, экспериментальные данные свидетельствуют, что в пределах диапазона до 10 миллиардов сохраняется близкая к линейной зависимость x от числа n по такой формуле: x=n·3,6·10-12.
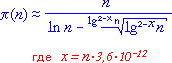
Сразу введем это новшество в код компьютерной функции NewPrimeCount:
function NewPrimeCount(N: extended): extended; var X: extended; begin // делаем заданное число целым и положительным N := abs(int(N)); // для чисел N=0 и N=1 расчет не имеет смысла Result := 0; if N < 2 then exit; // иначе вычисляем по новой формуле X := N * 0.0000000000036; Result := power(log10(N), 2 - X); Result := power(Result, 1/Result); Result := N / (ln(N) - Result); end;
И посмотрим на сводную таблицу:
Ситуация значительно улучшилась. На этом пока можно остановиться, напоследок предложив читателям еще одно любопытное наблюдение. В очередной раз вернемся к первой таблице. Заметим, что числа в последнем столбце гораздо точнее равны не просто удвоенному показателю степени числа n по основанию 10, а сумме удвоенного показателя степени и удвоенному десятичному логарифму этой степени, то есть 2·lg n+2·lg lg n.
Если посмотреть на формулу такого приближения, напрашивается аналогия с уточнением Лежандра. В том случае логарифмика ln n целиком смещалась вниз на 1,08366. Мы сделали, чтобы она еще и "разгибалась". А в этом случае логарифмика lg n расположена итак низко на графике, поэтому она должна смещаться вверх (в знаменателе видим знак +). Кроме того, смещение уже осуществляется с "разгибом", то есть +lg lg n.
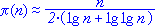
Очевидно, предложенное "разгибание" окажется чрезмерным при больших n, поэтому приходим к заключению, что множитель 2 тоже не есть статичный коэффициент. Он должен постепенно уменьшаться. Вероятно, характер его уменьшения в некотором роде похож на поведение кривой предела y=(1+x)1/x. Во всяком случае у желающих самостоятельно отыскать пути к еще более лучшим и наипростейшим уточнениям асимптотического закона распределения простых чисел имеется широкое поле для исследований.
Дмитрий Сахань, 7 января 2006 года