Разделы
Счетчики
Artificial Intelligence - Искусственный Интеллект... мы тоже работаем над этим!
На этой странице автор делится опытом и размышлениями о проблеме создания Искусственного Интеллекта (ИИ), причем не только в оригинальной теории, но я в практических применениях.
Содержание
- Вступление
- Задача
- Что лежит в основе проектируемого ИИ
- Эмоции/стиль поведения проектируемого ИИ
- Основы восприятия и ассоциативные связи
- Атом памяти
- Память ИИ
Вступление

А толчок к началу размышлений и практических выводов о разработке собственной модели ИИ послужило крайне малое на сегодня предложение устройств с применением ИИ на массовом рынке. Удивительно, что при повальной компьютеризации, наличию "умных" высокопроизводительных PDA, сотовых телефонов, программируемых телевизоров и микроволновых печей, изделий типа SONY-вской собачки AIBO крайне мало! И это в нашем продвинутом 21 веке!
Вместо думающих и поступающих РАЗУМНО созданий, сегодня на рынке предлагаются лишь хорошо спроектированные автоматы- да! оснащенные всякими сенсорами и моторчиками, и вроде ненатыкающиеся на ножки стульев, но все же автоматы, использующие в принципе одни и те же заранее заданные алгоритмы типа: "ткнулся носом в стенку - поверни вправо и попытайся ее обойти..." А может в эту сторону вообще не надо идти? Или может сразу повернуть налево? А эти "крутые" роботы-пылесосы или газонокосилки? Прочитав инструкцию и принцип действия, я подумал: "а что пылесос будет делать если наткнется на мои разбросанные по ковру тапки?" Или я сначала должен убрать с пола тапки, носки, журналы, утюг, гантели, большой спортивный мяч жены и т.д. и только потом "любезно пригласить" робота-помощника?.... Может мне вообще самому подмести? Пусть он отдохнет... за такие деньги!
В то время, когда человечество совершает прорыв во всех сферах: компьютеры, космос, биология, устройства с ИИ находятся в зачаточном состоянии. И я не имею ввиду автоматы, собирающие авто на конвейерах Японии- это только автоматы.

Даже прочитав последние дайджесты НАСА о марсоходах, недавно стартовавшихк красной планете, я понял, что и тут-то все также обстоит примитивно. По-существу, это те же радиоуправляемые модели, задача которых только и состоит в том, чтобы не натыкаться на камни в моменты радиомолчания с Земли! Правда, с технической точки зрения, шасси марсохода выполненно на 5!
Короче, я не хотел бы бесконечно хаить сегодняшние "достижения" в области создания устройств с ИИ, а поделиться с Вами, читатель, собственными размышлениями на эту тему.
Задача
Задача проста и сложна одновременно- создать нечно похожее по уму на 3-х летнего механического ребенка, ни или хотя бы опытного зрелого дрессированного пса. Или по-другому: поработать на проектом создания самообучающейся модели ИИ.
Проста- потому что ничего не надо изобретать- все изобретено и показано нам, как это делается самим Богом.
А сложна- потому что необходимо нашими современными примитивными методами и техникой сымитировать механизмы человеческого мышления, зрения, слуха, эмоций, принципов принятия решений и т.п.
Что такое примитивные? Ну, например, современные цифровые фотокамеры дают разрешении 5-6 мегапикселов... Человеческий глаз содержит около 140!! мегапикселей. Ну и что? Нам пока вообще надо 300 тыс. Хотя дело не в этом. Можно предусмотреть, что с развитием процессорной базы, разрешающая способность сенсоров будет адекватно увеличиваться...
Основные принципы внутренней организации, развития и деятельности такого ИИ соответствуют человеческому, примером может стать родившийся ребенок с набором инстинктов, "сенсоров", биологических примитивов и главное способностью обучаться.
Поэтому прежде чем решить ту или иную проблему в будущем, нам надо будет просто заглянуть в себя или в крайнем случае в глаза ребенку на улице... Любые вопросы бедем сначала относить к человеку! Как это делает он? Как это у него получается? Как он этому научился? и т.п.
Вот именно, будущий робот (назовем его так) будет туп от рождения и обладать ТОЛЬКО:
- "врожденными" инстинктами;
- алгоритмами познания мира;
- алгоритмами накопления и анализа полученных знаний;
- алгоритмами принятия решений;
- базовыми "примитивами" и т.п.
Задача всей его "жизни" (и это один из врожденных инстинктов!)- учиться. И не только самому! Человек (пусть это будет хозяин) должен обучать его, "цацкаться" с ним, выгуливать и т.д.- то есть возиться с ним, как с обычным ребенком...
В этом вся суть.... И никаких нейросетей...
После проработки на бумаге основных принципов и разработки блок-схем и алгоритмов, начнется этап выбора аппаратных и программных элементов будущего "робота", например, тип основного контроллера, необходимый набор и качество сенсоров, устройства хранения информации, шасси робота- тележка, шагоход, гексаход, андроид и т.д. Также важен выбор SDK набора для будущего программирования: С++, Дельфи и т.п.
Примерный план работы над проектом может быть таким. Разработка детальных алгоритмов:
- считывания сенсорной информации
- ее предварительная обработка
- принципы хранения, учитывая семантику и ассоциации
- принципы создания и отработки графа ассоциативных связей
- принципы планирования действий
- схемы и стили поведения
- механических примитивов (позиционирования, отход, подход, поворот....)
- После этого, постройка механического прототипа, установка моторики и сенсорики.
- Шлифовка алгоритмов с учетом построенной механики
- Написание программного кода
- Отладка
- Запуск в жизнь- вот именно, никто ему в "голову" Ленинскую библиотеку вводить не будет! Только алгоритмы самообучения (или даже принудительного, или по запросу...). С ним надо будет обходиться как с ребенком- учить, выгуливать, показывать, бить, ласкать и тд.
- Анализ приобретенного опыта
- Коррекция алгоритмов
- Попытка искусственно "подкачать" новый опыт
- Запуск обратно в свет
- Наблюдение
- Добавление новых устройств, сенсоров, манипуляторов и проч.
Список задач можно продолжать.
В результате у нас получится существо, которое еще надо будет воспитать! Его "аппарат" не будет зависить от языка, на котором говорит хозяин- ему он научится, ни от среды, где "робота" будут воспитывать- он ее познает... Более того, попав уже будучи "зрелым" в другие, например, англоговорящие, руки "робот" сможет научиться и новому языку и уже САМ решит забыть ему старый или все-таки записать где-нибудь на "корочке"... Главное- никаких ограничений! Например, сегодня можно использовать флэш-память на 512Мб, а завтра скажем на 5Гб, процессор на 2Гц, а завтра на 10Гц- вот и все!
Что лежит в основе проектируемого ИИ
Итак, ответим себе на вопрос: что представляет собой только что родившийся человек?
Это биологическая машина с набором врожденных инстинктов, некой генетической памятью (ее мы пока опустим), сенсорикой и примитивной моторикой (типа дали сиську-надо сосать, игрушку-хватать, глазами-моргать и тд)... Все! Как это не странно! Он ничего не знает об истории человеческой цивиллизации, он не знает что такое чайник или яблоко, он не знает как его зовут- свежо и пусто в доме том... Правда стоит отметить, что САМ создал уникальную биомашину способную всему научиться, создавать, размножать и тд.
С первых же своих минут, новый человек начинает познавать мир. Причем несколькими методами:
- сам
- его учат
- сам спрашивает
- делает умозаключения
вопрос: что еще?
А почему он это делает? Потому что так велит ему инстинкт!!! Таким образом в простейшем случае (как например, с собакой) существо подчиняется инстинктам. Чем лучше удовлетворяется тот или иной (или все сразу) инстинкты, тем ближе существо к... счастью (или совершенству- как угодно).
У человека масса инстинктов. Но если разобраться основополагающих несколько:
- самосохранения
- познания
- размножения
вопрос: что еще?
Соотвественно внесем в нашего "робота" набор первичных инстинктов, которые потом будут задавать весь уклад его "жизни". Они очевидны! и расставлены в порядке приоритетности:
1. "Животные" инстинкты. Назовем их Nature. Это, например, чувство "голода". Пока мы не создали вечные источники питания, роботу надо подзаряжаться. Будем контролировать уровень батарей. Чем меньше этот уровень, тем "громче" кричит инстинкт Nature, тем больше он опеределяет текущее поведение или эмоцию робота. (см ремарку А ниже). Кроме того, сюда можно отнести "усталось" робота. К примеру, переполнение (или хаос) в буферном ОЗУ. Необходимо эту информацию рассовать по базе знаний, очистить, обобщить и тд. Короче- пора спать! (см. ремарку Б ниже)
вопрос: что еще можно отнести к Nature?
2. Самосохранения. Safety. Вступает в силу при превышении критичных параметров системы. Например, для звука это динамический диапазон. Резкий громкий звук сигнализирует опасность, как и слишком яркий свет. Сильный удар воздействует на тактильные датчики робота и также сигнализирует опасность. Если установить дополнительные датчики (температуры, наклона, поднимаемого веса для манипулятора, и даже экзотические, типа радиационный), то можно будет снимать критические параметры и с них. Этот и Nature инстинкты входят в группу Evil- Зло.
3. Инстинкт служения хозяину (людям). Devotion (Love). Это ведь робот! Не будем повторять судьбу Франкенштейна или Терминатора! Введем сильный инстинкт любви к человеку. Роботу должно "нравиться" играть, учиться, гулять, развлекать и проч. проч.
Вопрос: Как измерить величину степени удовлетворения данного инстинкта?
4. Познания. Назовем его Explore. Чем в основном занимается робот? Познает мир и служит хозяину (людям). В простом случае, сначала познает, потом анализирует, потом служит... В периоды, когда роботу не угрожает опасность, он занимается изучением окружающего мира.... А когда угрожает, он делает это с удвоенной энергией- Active Explore. Какова мера удовлетворения инстинкта Explore? Очень просто! Это кол-во новой полезной информации поступающей в ед времени. Если тупо: кол-во новых записей и ассоциаций в БД/мин (час?). Кстати, тут надо подумать. Может рассматривать градиент? Положительный- значит процесс познания (exploration) ускоряется, отрицательный- снижается... Эти два инстинкта входят в группу Добро (Good).
5. вопрос: что еще?
Понятно, что чем больше мы заложим базовых инстинктов, тем более богаче станет "внутренний мир" и стили поведения робота в будущем. Ибо результирующее состояние (эмоция) ИИ будет величиной интегральной, а не абсолютной, типа: Страх на 1 ед больше, значит все остальное пустяк! Нет! Мы реализуем анализ всех входящих посылок от всех инстинктов, с их весовыми коэффициентами конечно. Таким образом, робот будет "бояться" лезть в огонь, но все же полезет, т.к. там необычайно интересно (Explore) или там орёт хозяин (Love).
Это база. Что делать с ней дальше- в следующей главе...
***********************************************************
РЕМАРКА А: Например, робота зовут погулять на улицу (удовлетворить следующий инстинкт Explore), а уровень батарей мал. Робот "знает" по предыдущему опыту, что время гуляния превышает оставшееся время работы батарей. Столкнулись два инстинкта. Победит сильнейший.
РЕМАРКА Б: Вы задавались вопросом, зачем спит человек? Что такое сон? и что происходит во время сна? Конечно, медики скажут нам об этом многое! Но разберем вопрос с "машинной" точки зрения. Почему утром мысли бегут быстрее, память лучше, а к вечеру появляется усталось, потеря внимания, и тугомыслие? На мой взгляд, все дело в оперативной памяти (ОП), которую мы используем весь день и перерабатываем, очищаем, сортируем, кладем в долговременную память ночью во время сна. Отсюда и ассоциативные сны и кошмары. У людей с бОльшей ОП мозг работает дольше и быстрее без признаков утомляемости. Возьмите в пример грудного ребенка. Ему требуется спать каждые 2-3 часа... В том числе и для очистки пока еще маленькой ОП. Так и у робота. Понятно, что бОльшую часть вычислений он ведет в быстром ОЗУ и когда она заканчивается/переполняется (а за этим надо программно следить), роботу необходим сон- в "машинном" понимании слова.
Эмоции/стиль поведения проектируемого ИИ
Итак, мы выяснили, что инстинкты будут "двигать" роботом. Инстинкты это:
1. Nature
2. Safety
3. Devotion (Love)
4. Explore
Определим эмоциональные признаки и/или стиль поведения нашего ИИ, в зависимости от степени удовлетворения каждого из инстинктов.
1. Nature
- Memory Maintenance (очистка и приведение в порядок ОЗУ, сон)
- Hungry (заканчиваются батареи)
2. Safety
- Circumspection (настороженность, осторожность, осмотрительность, внимательность)
- Fear (страх, мобилизация)
- Danger (опасность, спасение)
3. Devotion (лучше подходит, чем Love)
- Passive Dialogue
- Active Dialogue
- Service
4. Explore
- Passive Exploration
- Active Exploration
- Training
В простейшей модели, которую мы рассматриваем, робот может находиться лишь в одном из этих состояний, что конечно обедняет эмоциональную палитру существа. Хотя даже в нашем случае он может находиться в одном из 11 состояний.
Конечно, в идеале стоит ввести смешанные эмоции, а еще лучше описать состояния учитывающие комбинацию параметров удовлетворения ВСЕХ инстинктов. Так как у нас кол-во инстинктов 4, а стандартных состояний-примитивов для каждого по 3, получается, что робот будет обладать 3 в 4-й степени (81) стилями поведения!
Вот почему мы пока ограничились лишь 4-мя основными инстинктами.
Что все это значит и для чего это нужно?
Для того чтобы реализовать типовую блок-схему работы ИИ:
- Настройка
- Восприятие
- Анализ
- Планирование
- Решение
- Действие
На какой из этих пунктов воздействует результирующее состояние "души" робота?
Да на все сразу!!!
На этапе "Настройка" в состояниях Active Explore, Fear, Danger и др. происходит более точное позиционирование, настройка сенсоров, подкачка доп данных в ОЗУ, которые могут понадобиться в дальнейшем.
На этапах "Восприятие" и "Анализ" изучается бОльшее кол-во возможных объектов.
"Планирование" идет глубже, вовлекается больше знаний и опыта для правильного "Решения". Похоже на шахматы. На втором уровне, когда машина продумывает на два хода вперед, играть еще можно... а вот на четвертом уже трудно...
Аналогично у человека: сама по себе эмоция или текущее состояние ничего рационального не несет. Зато позволяет всем остальным процессам идти с большей или меньшей скоростью, с большим или меньшим качеством.
Таким образом, подытожим:
У нас имеется 4 инстинкта, степень удовлетворенности которыми характеризуется своим коэффициентом- от 0 до 3. ("0"- инстинкт игнорируется, не применяется, не важен, не воздействует и тд). Каждому коэффициенту соответствует свое описание (алгоритм и тп) эмоционального состояния или стиля поведения.
В дальнейшем мы покажем, что выработка результирующих показателей коэффициентов будет складываться из нескольких составляющих:
- набора текущего Current Set
- набора события Event Set*
- набора из опыта Experience Set**
* Набор Коэффициентов Nature, Feаr, Devotion и Explore полученные после отработки события
** Набор Коэффициентов Nature, Feаr, Devotion и Explore взятые из предыдущего опыта, т.е. из БД ассоциативной памяти.
Какой можно привести пример из жизни?
Представьте Вы идете по дороге. Ваш взгляд рассеяный, Вы спокойны. Организм заботится лишь о том, чтобы Вы шли действительно по дороге, в правильном направлении и не стукнулись случайно лбом о столб. Про таких говорят: " идет, щелкает клювом...".
***Применительно к роботу: состояние Passive Exploration
Вдруг, мельком (именно мельком- Ваш взгляд ведь рассеяный) Вы замечаете что-то блестящее на дорожке! Произошло событие! Разберем его сообразно нашей модели. Вы не опознали ничего знакомого, Вы не почувствавали опасности, кроме чего-то блестящего на дороге ничего не произошло (не раздался хлопок, на голову не упал кирпич и проч.).
***Применительно к роботу: такое событие в режиме Passive Exploration отработаться не должно!
Однако, у нас в памяти вдруг что-то шевельнулось! Оказывается неделю назад Вы точно также нашли на дорожке золотой червонец! (то есть записали на "корочку" связь "событие-следствие"). Конечно, Вы тут же остановитесь и начнете изучать объект детально.
***Применительно к роботу: попытаемся найти в БД образ блестящего предмета. О чудо! Нашли! Берем от туда Experience Set, в котором обнаруживается, что коэффициент Explore равен 2 - Active Exploration, в алгоритм поведения которого введена процедура детального изучения картинки и/или мех действий: наезд, отъезд, фокус и проч.
Таким образом, при интеграции все трех составляющих Current Set, Event Set, Experience Set мы получим такой же стиль поведения робота, как и поведение реального человека в данной ситуации.
Основы восприятия и ассоциативные связи
Давайте вернемся к нашему человеческому малышу. Как он вопринимает мир первые секунды появления на свет? Что и как откладывается в его головке? Как он приходит к осознанию, что я это Я, меня зовут Петя, это моя мама, именно слово «мама», а не трактор или чайник…
Мы уже и не помним, какой это был калейдоскоп лиц, цветов, красок, какофония звуков, переменчивых ощущений: тепло и холод, сухо и мокро, темно и светло и тд. Хаос! Ничего не понятно! И страшно! От того и крик, и крик, и крик…
Но как только малыш начинает уметь фиксировать взгляд и различать отдельные звуки, привыкать к температурным и «влажностным» изменениям окружающей среду, начинается самое интересное! Именно с этого момента мы и начнем, ибо наш робот де-факто умеет и фиксировать, и различать.
«Петя, Петечка! Сыночек!»- слышит малыш и видет лицо матери.- «Это мама твоя пришла! У-тю-тю, у-тю-тю…». И так изо дня в день, тысячу раз. Вопрос: что отложится в голове ребенка? Какие возникнут ассоциации? Очень просто:
- слово «Петя», наибольшее кол-во повторений;
- слово «мама», большое кол-во повторений;
- слово «сыночек», малое кол-во повторений;
Что мы забыли? Ну конечно же- «лицо матери»! Так сказать… изображение, образ. И при чем очень большое кол-во повторений! Меньшее, чем слово «мама», но очень близкое по общему количеству (это логично, поскольку звуки мы слышим всегда, а видим соответствующее изображение реже).
Ребенок еще не умеет говорить, но если мы «вставим» ему в мозг «электроды» и спросим напрямую у мозга: «Кто ты?», «Что или Кто для тебя важен?», каков будет ответ? Наверное, «Кто»- это слово «Петя», как наиболее часто повторяемый образ, самая высокая НОДА в нашем пока еще скромном ГРАФЕ ассоциаций. Наверное, «Важно»- это слово «мама» и изображение «лицо матери», т. к. эти ноды также имеют большое кол-во повторений, следующих сразу за самым частым, ЭГО- слово «Петя».
Нарисуем наш граф в виде:
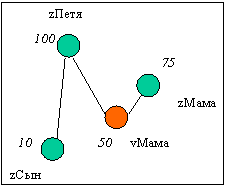
где z- звуковой образ, v- видео/фото образ; цифры у узлов графа означают кол-во повторений, цитируемость образа.
Мы видим, что звук «Петя» имеет самый высокий индекс цитирования (кол-во повторений) и связан с видео «Мама» и звуком «Сын».
Небезосновательно утверждение, что познание мира происходит от простого к сложному. Сперва мы получаем базовые знания, затем изучаем детали, делаем выводы. Рассмотрим другой пример, выбрав в качестве «базовых» знаний представление о… цвете- красный, синий, желтый и тд. Роботу показывают красный лист бумаги и говорят слово «красный». Аналогично, обучают другим цветам. Наш проектируемый ИИ должен создать такие простные ассоциации:
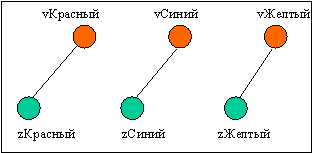
После обучения базовым понятиям, покажем нашему ИИ красную розу и скажем фразу «красная роза». Как в этом случае должен повести себя ИИ. В наших силах сейчас разработать определенные правила создания более сложных ассоциативных связей.
Робот получает картинку vКрРоза и пытается найти такую же в существующей БД образов. Предположим такой узел не найден.
Тогда робот создает новую ноду vКрРоза
Дальше разбор входящей информации может пойти двумя путями. Во-первых мы можем анализировать более детально полученную картинку vКрРоза. А во-вторых, проанализировать звук фразы «красная роза». Главное, чтобы результирующий граф связей оказался одинаков!
Предположим, что начался процесс анализа фразы. Мы выделили слово «красная» и начинаем искать его в БД. Благодаря предварительному обучению, слово найдено- это нода zКрасный. Отлично, увеличиваем индекс цитируемости этой ноды. Она, как мы знаем, уже связана с изображением красного цвета vКрасный, что может понадобиться нам в будущем. Продолжаем анализировать фразу и выделяем слово «роза». Ее нет еще в нашей БД, поэтому создается очередная нода zРоза. Логично, что при этом устанавливается связь с vКрРоза.
Предположим, что начался процесс анализа картинки vКрРоза. Логично предположить, что раз роза красная, то при детальном анализе мы выявим «чистый» красный цвет vКрасный, узел которого уже существует. Увеличиваем индекс цитируемости этой ноды. Логично, что напрашивается мысль связать ноды vКрРоза и vКрасный. И это правильно! Но как? Представим себе, что предыдущего процесса анализа фразы «красная роза» не было. Связанны только vКрасный - zКрасный и vКрРоза – zРоза, а также наша новая ассоциация vКрРоза – vКрасный:
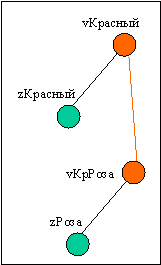
Представим, что в дальнейшем робот услышал фразу «красная роза». По идее, мы с помощью данного графа должны безошибочно выйти на узел vКрРоза. Однако, этого не получается, т.к. видео-узлы в данном случае равносильны. Не помогает и привлечение индекса цитируемости. Конечно, нода vКрасный будет гораздо популярнее.
Поэтому, в рассматриваемом нами случае анализа картинки vКрРоза необходимо установить направление связи- от базовых элементов графа к более сложным. Давайте построим на таком принципе более разветвленный граф связей и протестируем различные ситуации с тем, чтобы в результате каждый раз получить единственный ответ:
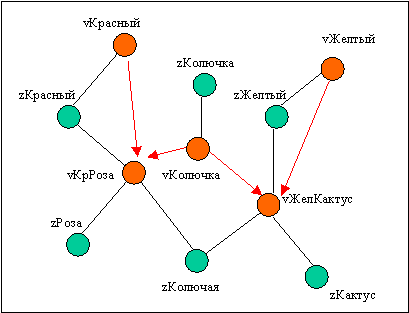
Увидев изображение красной розы, робот теперь может «смело» предположить, что это роза, красная, колючая и может содержать в себе красный цвет и колючки. Если будет, например, активизирован стиль поведения Active Exploration или Search, ИИ спрогнозирует появление этих объектов и будет готов к дальнейшей обработке.
И наоборот, если робота специально не обучать, “что вот этот кактус желтый”, наш ИИ, зная базовые определения и граф связей, “вычислит”, что услышанная фраза “желтый кактус” указывает на имеющуюся в памяти ноду vЖелКактус.
Аналогично, если робот увидет Колючку. Однозначно он сказать не может кому или чему онапринадлежит. Но может сделать прогноз, что Красной Розе или Кактусу. Таким образом, поиск объектов на сцене может ограничиться лишь поиском только двух! простым сравнением реальности с образом в БД. Мы будем еще и еще раз возвращаться к построению различных графов в дальнейшем, но сейчас определим, что из себя представляют узлы графа.
Атом памяти
Как я уже показал, наше существо должно стремиться к познанию мира, используя прежде всего свои сенсорные возможности. Образы, снятые с этих и датчиков, будут поступать в блок обработки и предварительного анализа, откуда- сначала в Оперативную Память, а затем в долговременную базу данных (БД) образов и ассоциаций. Структура каждой такой записи сложна и на эти данные впоследствии будет опираться вся работа ИИ по осмыслению информации полученной извне. Такую запись будем называть Атом Памяти (АП) .
На основе всего вышесказанного, попытаемся разобраться какова должна быть структура этого АП, какие элементы должна содержать эта запись, каков ее предполагаемый объем и тд.
На рисунке ниже изображена предполагаемая структура АП:
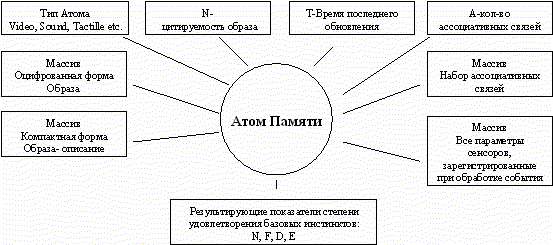
1. Типа Атома. Параметр, определяющий тип данных. Как мы уже показали, визуальные данные содержат больше информации, а потому более приоритетны перед звуковыми или прочими. Впоследствии, оценивая полученный граф связей, мы увидим что к узлам Video будут «тянуться» Атомы Sound и другие, более «примитивные» данные.
2. N- число, показывающее сколько раз интеллектуальная система сталкивалась с этим Атомом в результате обработки поступающих с сенсоров данных. Каждый раз когда ИИ распознает «желтый кактус», N- индекс цитирования соответствующего Атома увеличивается на одну единицу.
3. Т- сюда вносится текущее время при создании или достоверном распознавании образа.
4. А- просто количество ассоциативных связей Атома с другими Атомами
5. Shape- предварительно оцифрованная информация, снятая с датчиков в упакованном виде. ИИ может в любой момент взять эти данные для анализа, сравнения с другими данными или воспроизведения.
6. Descriptor- очень важный массив данных, являющийся неким описанием Shape. Эти данные – результат анализа графического или звукового файла, его особенностей, закономерностей и т.д. Ну, например, для звукового образа это может быть его частотная характеристика, динамический диапазон, для графического- палитра цветов, баланс белого, гамма, уровень яркости и контрастности и проч. Современные приложения типа Photoshop и CoolEdit помогут подсказать массу несложных методов таких описаний. Descriptor вводится в Атом, чтобы снизить время и сузить объем поиска нужного образа в обширной БД. Оцифрованная и обработанная по общим правилам текущая информация с сенсоров передается в блок поиска. В первом приближении идет поиск именно по Описателям. Более-менее похожие Атомы выделяются системой и только затем происходит точное сравнение файлов изображения или звука с такой же информацией из БД. Таки образом, удается значительно снизить время поиска. По объему Descriptor на порядкок, а то и на два меньше, чем реальный образ. Правила и методы создания такого описателя подробно будут рассмотрены ниже.
7. Semantics Array- массив семантических связей Атома с другими Атомами. Простой массив указателей, учитывающий направление такой связи.
8. Sensors Dump- здесь сохраняются все текущие параметры вспомогательных сенсоров. Опять же, при каждом обновлении этих данных возможна их замена новыми или усреднение.
9. NFDE- четыре ячейки, содержащие коэффициенты степени удовлетворенности каждым инстинктом после этапа завершения обработки события. Так сказать, конечная реакция ИИ на внешнее воздействие, событие. Например, давайте научим робота «боятся» воя сирены. Сделать это можно по разному. Во-первых, просто на бОльшой громкости проиграть серену над «ухом» робота. Система оцифрует звук, произведет анализ, создаст Атом zСирена, опросит вспомогательные сенсоры и выявит превышение предельно-допустимого уровня громкости звука в децибелах. Инстинкт Safety, стоящий на страже самосохранения выдаст корректирующий (повышающий разумеется) коэффициент страха F. Остальные параметры N, D, E остануться неизменными. Во-вторых, можно проиграть серену с обычной громкостью, но при этом сильно воздействовать на другие «органы чувств» робота, например, сильно стукнуть. Полученную связку «звук-удар» также отработает блок Safety и получит такой же (а может и более весомый…) повышающий коэффициент F. Ячейки NFDE не обязательно заполняются сразу! Предположим, что робот услышал звук звонка Вашей входной двери. Ну и что? Ничего особенного. Атом zЗвонок сформирован, а ячейки NFDE пусты. Тем не менее произошло событие и система запускает внутренний таймер и какое-то время ждет продолжения. Заходит хозяин! Робот распознает его и инстинкт Devotion увеличивает коэффициент D. И только после этого конечные значения NFDE заносятся в Атом zЗвонок. Таким образом, мы выяснили, что определяющим фактором при котором фиксируется состояние коэффициентов NFDE , является градиент изменения этих значений. Если, все время “страшно”, коэффициент F, скажем, равен 5, то градиент будет равен 0- изменений нет. Если становиться еще страшнее и значение F поползло вверх и стало равно 7. Градиент станет равен +2. Именно эта величина и запишется в соответствующую ячеку NFDE.
Конечно, можно добавит еще данные в АП, которые будут полезными нам в будущем. Какие?
За время своей «жизнедеятельности» наш робот будет все время пополнять БД новыми данными и их количество будет возрастать иногда лавинообразно. Наша с задача найти правильный баланс между желанием сэкономить на памяти и развитием робота, как интеллектуальной системы. Ясно, что чем больше знаний об окружающем мире он получит (изучит, проанализирует и тд), тем больше он будет казаться разумным и адекватнее реагировать на события вокруг него. С другой стороны, неимоверный объем информации в БД надо чем-то обрабатывать и в конце-концов мы упремся в недостаток производительности CPU, когда реакцию ИИ придеться ждать целый час!
Введение в АП вспомогательных параметров, более сложная организация БД (см. ниже), оптимизация уже существующей информации в БД на основе анализа схожих данных и объединения их в группы, разработка правильных алгоритмов обработки событий, передача части работы аппаратным контроллерам и т.д., существенно снизит время реакции робота. Многое из этого мы обсудили и будем обсуждать ниже.
А пока попытаемся оценить объем одного АП. Ясно, что для видео- и звуковых данных он будет разный. На первых порах ограничимся разрешением видео-картинки в 640х480 точек, 16-ти битный цвет и частотным звуковым диапазоном 300-4000Гц. Упакованный JPEG файл такой картинки будет занимать около 50-60кБ. Звуковой файл также упакованый, например, 3:1 – не более 2-5кБ. Остальные данные в АП не занимают много места. Разве что массив Semantics Array. Но даже для АП с тысячью связей такой массив займет около 2кБ.
Таким образом, приблизительный объем vАтома будет равен 70кБ, zАтома - 7кБ.
Память ИИ
Итак, мы предположили, что наша интеллектуальная система будет использовать более быструю Оперативную Память (ОП) для предварительной обработки и накопления информации, о ней мы поговорим позднее, и Долговременную Память (ДП) для собственно хранения всей БД образов и ассоциативной связи.
Если ОП имеет сравнительно небольшой объем и может быть разрушена в непредвиденных ситуациях (сбоев питания и проч.), ДП должна иметь гораздо больший объем и размещаться на долговременных носителях типа жесткий диск или, как я вижу наиболее приемлимым, флэш-картах, которые легко можно заменить и модернизировать.
Учитывая нашу оценку объема одного видео-Атома памяти в 70кбайт, на доступную сегодня флэш-карту в 1Гбайт уместиться более 14 тысяч таких Атомов, а всего смешанных с Атомами звука и других датчиков втрое-вчетверо больше! Так что простора на сегодня хватает.
Наверняка, любой процессор в конце концов «захлебнется», производя хотя бы элементарную операцию поиска нужного Атома в таком огромном массиве. Поэтому структуру хранения данных в ДП необходимо оптимизировать. Обратимся опять к «устройству» памяти человека. Образы, которые мы видели сегодня, пять минут назад наиболее «живые», яркие, полны деталей. Номер телефона только что надиктованный Вашим другом ясно запечатлен в голове. Но со временем хватка ослабевает и в итоге через неделю мы едва ли сможем вспомнить номер целиком или нарисовать случайное лицо, увиденное в толпе месяц назад.
То есть фактор времени события, времени создания (или обновления) образа в Вашей памяти играет большую роль в дальнейшем его поиске. Как с этим бороться? Помните пословицу: «Повторенье- мать ученья». Повторив номер телефона или какой-нибудь куплет из песни несколько раз, мы тем самым улучшаем память, способность вспомнить эту информацию позднее. Итак, фактор повторяемости (цитируемости) образа памяти также значительно влияет.
Предлагаю рассмотреть структуру организации ДП нашей системы:
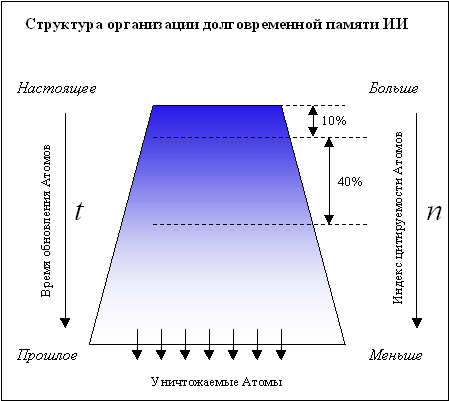
Она представляет собой трапецию, на вершине которой собираются Атомы памяти как наиболее цитируемые, так и наиболее современные. Простая операция сортировки соответственно по n и t дает нам такой результат. Теперь в зависимости от производительности системы на данный момент, ИИ начинает поиск нужного Атома именно в вершине трапеции памяти, скажем в 10% от общего объема. Если поиск неудачен, то ИИ сам решает стоит ли продолжать поиск, скажем в следующем 40% слое памяти или нет. На рисунке видно, что при заполнении всей ДП, Атомы-аутсайдеры могут быть уничтожены интеллектуальной системой полностью или частично, например, стерт “тяжелый” оцифрованный образ, занимающий до 90% от всего объема Атома.
Таким образом, опираясь опять же на человеческую модель, мы достигли некой аналогии (что уже хорошо!), сузили объем поиска нужной информации и сократили время, а также решили проблему освобождения от старой, невостребованной и значит ненужной информации.
Источник: