Разделы
Рекомендуем
• Транспортная литература: информационные стенды. Вывески. Крышные установки. Буквы.
Счетчики
Глава1. Естественно-языковые интерфейсы к структурированным источникам данных
- 1.1 Основные характеристики и составляющие части ЕЯ-интерфейсов
- 1.1.1 Сравнительный анализ ЕЯ-интерфейсов и традиционных интерфейсов к СИД
- Преимущества ЕЯ-интерфейсов
- Недостатки:
- 1.1.2 Критерии качества ЕЯ-интерфейсов
- 1.1.3 Критерии стоимости построения и сопровождения ЕЯ-интерфейса
- 1.1.4 Вопросы портируемости
- 1.1.5 Основные составные части ЕЯ-интерфейсов к СИД
- 1.2 Подходы к анализу ЕЯ-запросов к СИД
- 1.2.1 Системы, основанные на шаблонах
- 1.2.2 Синтаксически-ориентированные системы
- 1.2.3 Системы с семантической грамматикой
- 1.2.4 Системы с промежуточным языком запросов
- 1.2.5 Семантически-ориентированный подход
- 1.2.5.1 Основные принципы
- 1.2.5.2 Возможная архитектура системы
- 1.3 Средства описания предметной области
- 1.3.1 Соотношения знаний о языке и знаний о предметной области в ЕЯ-интерфейсе
- 1.3.2 Предметная область и ее отражение в структуре и содержимом источников данных
- 1.3.3 Расширения и ограничения как метод задания элементов МПО
- 1.3.4 Средства описания концептуальной схемы источника данных
- 1.3.4.1 Семантические сети и фреймы
- 1.3.4.2 Диаграммы сущность-связь
- 1.3.4.3 Resource Description Framework (RDF)
- 1.4 Наиболее распространенные типы СИД
- 1.4.1 Реляционные СУБД
- 1.4.1.1 Основные структурные элементы
- 1.4.1.2 Целостность данных в РСУБД
- 1.4.1.3 Транзакционность
- 1.4.1.4 Нормализация баз данных
- 1.4.2 Объектные СУБД
- 1.4.2.1 Архитектура СУОБД, согласно ODMG-93
- 1.4.2.2 Характеристики системы типов ODMG-93
- 1.4.3 Представление СИД в формате XML
- 1.4.3.1 Структура XML
- 1.4.3.2 XML-схемы
- 1.4.3.3 Пространства имен
- 1.4.3.4 XML-ссылки
- 1.4.3.5 XML-стили
- 1.4.3.6 Некоторые применения XML
- 1.5 Языки запросов к СИД
- 1.5.1 Цели создания формальных языков запросов
- 1.5.2 Структура запроса к СИД
- 1.5.2.1 Источник
- 1.5.2.2 Дано
- 1.5.2.3 Получить
- 1.5.2.4 Упорядочить
- 1.5.3 Элементы СИД и их обработка в запросе
- 1.5.4 SQL
- Операции реляционной алгебры
- 1.5.5 OQL
- 1.5.5.1 Основные принципы
- 1.5.5.2 Выражения для путей
- 1.5.5.4 Полиморфизм
- 1.5.5.5 Произвольная композиция операторов
- 1.5.6 XSL/XQL
- 1.5.6.1 Шаблоны форматирования
- 1.5.6.2 Задание поисковых шаблонов с помощью XQL
- 1.5.7 XML QL
- 1.5.8 RDF Query
1.1 Основные характеристики и составляющие части ЕЯ-интерфейсов
В современном информационном мире проблемы доступа пользователей к различным компьютерным источникам информации встают чрезвычайно остро. С возникновения первых компьютеров задача хранения данных была и остается одной из главных. И одновременно с появлением первых хранилищ данных появились системы, которые облегчали доступ к данным.
Под пользовательским интерфейсом к структурированным источникам данных в данной работе понимается система средств, облегчающих поиск, получение, просмотр и обработку информации из внешней системы - структурированного источника данных (СИД). Естественно-языковой интерфейс (ЕЯИ) - разновидность пользовательского интерфейса, который принимает запросы на естественном языке, а также, возможно, использует ЕЯ и для вывода информации (реакции системы на запрос пользователя).
1.1.1 Сравнительный анализ ЕЯ-интерфейсов и традиционных интерфейсов к СИД
В противоположность ЕЯ-интерфейсам, нетрадиционным с точки зрения распространенности, существуют другие виды пользовательских интерфейсов к СИД, которые можно назвать традиционными. Среди них:
- Интерфейсы с формальным языком запросов
- Интерфейсы с графическим построением запросов
- Интерфейсы, основанные на заполнении форм запросов
В интерфейсах с формальным языком запросов пользователь, для того, чтобы правильно задать запрос, должен, во-первых, знать синтаксис языка запросов (например, SQL), а во-вторых, знать устройство структурированного источника данных (например, реляционную схему базы данных). При работе с этим типом интерфейсов пользователь должен обладать достаточно высокой квалификацией. Опыт показывает, что такой квалификацией обладают лишь специалисты, проектирующие и создающие информационные системы, и сам термин "пользователь" с учетом современных тенденций здесь не совсем адекватен. Очевидно, ЕЯ-интерфейсы обладают большей гибкостью - один и тот же запрос обычно можно формулировать различными способами. Что немаловажно, ЕЯ-интерфейсы, как правило, обладают системой понятий - описанием предметной области, которая находится выше логического уровня хранения данных. Это позволяет абстрагироваться от деталей устройства той или иной базы данных как на уровне структуры, так и на уровне содержимого.
Средства графического построения запросов, которыми снабжаются многие "настольные" СУБД (например, Access, FoxPro), безусловно, обладают большим удобством - по крайней мере пользователь не должен держать в голове названия таблиц, полей и конструкции языка. Однако для работы с такими средствами необходим опыт и представление некоторых понятий, относящихся скорее к математике (например, термин связывания таблиц в реляционной алгебре), а не к предметной области, и иногда достаточно утомительные действия по заполнению форм. Так, в базе данных Access для того, чтобы сформулировать выражение AVG(PERSONNEL.SALARY), эквивалентный ЕЯ-фразе "средняя зарплата", требуется около 15 нажатий мышью. Неподготовленный пользователь обычно пасует перед системами, требующими сложных действий.. Пользователь по-прежнему должен представлять устройство базы данных. По сути, эти средства позволяют графически создавать формальные запросы.
Интерфейсы, основанные на заполнении форм запросов, являются более дружественными, по сравнению с формальными языками. Сама метафора формы и ее заполнения подразумевает, что пользователь сразу видит набор критериев и параметров поиска, а иногда и список возможных значений полей формы, это сводит к минимуму ошибки при вводе запроса. От предыдущего метода построения пользовательских интерфейсов данный отличается тем, что как правило, все необходимые запросы уже написаны разработчиком интерфейса, и пользователь, чтобы получить ответ, должен просто вставить недостающие значения. Так работают многие современные коммерческие приложения, работающие с базами данных - пользователю информация в системе доступна в виде нескольких типовых "срезов" информационного пространства. К недостатку систем, основанных на таком подходе, как и в предыдущем, также следует отнести необходимость наличия у пользователя опыта работы с подобными системами.
Преимущества ЕЯ-интерфейсов достаточно очевидны:
- Минимальная предварительная подготовка пользователя
- Простота задания запросов на ЕЯ во многих случаях
- Большая скорость создания запроса (отсутствует стадия формального задания запроса)
- Более высокий уровень модели предметной области
Более подробно рассмотрим недостатки ЕИЯ по сравнению с другими типами интерфейсов.
- Неоднозначность естественного языка приводит к множественности смыслов. Специфика естественного языка такова, что часто запрос может иметь несколько смыслов, о которых пользователь в момент задания запроса не знает. Формальные же языки лишены проблемы неоднозначности. Это свойство ЕЯ приводит к усложнению ЕЯ-интерфейсов и методов анализа, в противном случае ЕЯ-интерфейс получается слишком примитивным для реального использования.
- Недостаточная надежность анализаторов ЕЯ-запросов может привести к неправильному пониманию. Современные ЕЯ-интерфейсы далеко не всегда позволяют диагностировать причины неудач понимания. Причины этих неудач могут быть как в лингвистической сфере, так и в концептуальной. Например, запрос к кадровой базе "Кто получает больше Иванова" может привести к непониманию, если ЕЯ-интерфейс не умеет распознавать вложенные запросы (а в данном случае надо сначала получить значение зарплаты Иванова, а затем сравнить с ней зарплату сотрудников). Это случай лингвистической проблемы. Второй пример - "Как зовут жен сотрудников?" может привести к неудаче понимания, если ЕЯ-интерфейс не поймет, что имя супруга/супруги - это реальный атрибут сотрудника, но отсутствующий в данной базе данных. В данном случае налицо будет концептуальная проблема - ЕЯ-интерфейс должен уметь отличать реальную предметную область, которую имеет в виду пользователь, задавая ЕЯ-запрос, от той ее части или трансформации, которая представлена в данном источнике данных.
- Пользователь может иметь завышенные или заниженные ожидания от ЕЯ-интерфейса. Сравнительный анализ типов пользовательских интерфейсов (основанных на формах, с формальным языком запросов, графические) показывает, что в целях построения ЕЯ-интерфейсов превалирует желание максимально приблизить интерфейс к потребностям неподготовленного пользователя. Это несколько поднимает планку требований к дружественности и надежности ЕЯ-интерфейсов, поскольку пользователь, впервые столкнувшись с системой, понимающей естественный язык, слабо представляет, насколько интеллектуальна система. При этом ожидания к степени понимания ЕЯ может отличаться от реальных способностей системы в обе стороны - т.е. пользователь может спрашивать систему о том, чего она "не знает", а может "по привычке" использовать простейшие шаблонные формулировки запросов. В других же типах интерфейсов к СИД рамки того, что пользователь может делать с помощью интерфейса, видны, как правило, сразу.
Поскольку характеристики ЕЯ-интерфейсов и систем для их построения могут существенно различаться, то преимущества и недостатки ЕЯ-интерфейсов по сравнению с другими типами интерфейсов к СИД можно выделить довольно схематично, только на качественном уровне. Для сравнения подходов к построению ЕЯ-интерфейсов введем метрику показателей, характеризующих качество ЕЯ-интерфейсов к структурированным источникам данных.
1.1.2 Критерии качества ЕЯ-интерфейсов
Для сравнительного анализа подходов к созданию ЕЯ-интерфейсов рассмотрим такую качественную интегральную характеристику, как надежность. Под надежностью здесь понимается способность ЕЯ-интерфейса правильно понимать намерения пользователя по получению информации из источника, при условии, что пользователь корректно выразил потребности в виде ЕЯ-запроса. Надежность отражает правильность принципов, лежащих в методе ЕЯ-анализа, а также правильность (корректность) построения ЕЯ-интерфейса к конкретному СИД.
Любой ЕЯ-интерфейс имеет некоторое пространство правильно понимаемых запросов. Чем больше это пространство, тем большей полнотой обладает ЕЯ-интерфейс. Полнота - характеристика, тесно связанная с гибкостью интерфейса. Поскольку пространство ЕЯ-запросов весьма неоднородно, следует говорить о различных типах запросов, т.е. групп запросов, имеющих сходное строение. Гибкость - показатель того, насколько разнообразные типы запросов может понимать ЕЯ-интерфейс. Речь в основном идет о так называемых "трудных" типах запросов, в числе которых - вложенные, эллипсис, анафорические.
Другой важной характеристикой является дружественность интерфейса, которую можно определить как меру того, насколько ЕЯ-интерфейс удобен в работе, насколько корректно он может сообщать о проблемах понимания, может ли он помогать в переформулировке неберущихся запросов и т.д.
Все эти критерии можно объединить в наглядную схему, отражающую составляющие качества ЕЯИ (Рис. 1.1.2-1).
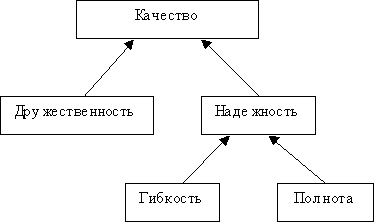
Рис. 1.1.2-1 Иерархия качественных характеристик ЕЯ-интерфейса
1.1.3 Критерии стоимости построения и сопровождения ЕЯ-интерфейса
Вышеперечисленные характеристики входят в оценки качества ЕЯ-интерфейса. Важным критерием при сравнении ЕЯ-интерфейсов является стоимость его создания, то есть необходимое количество усилий (времени), требуемых для его построения. Ранние ЕЯ-интерфейсы создавались для каждой базы данных отдельно, и, разумеется, их стоимость была очень большой. Все эти системы были экспеиментальными. Усугубляло проблему также то, что до конца 70-х годов не было единого универсального формального языка запросов к базам данных. Ранние системы понимания ЕЯ-запросов к СУБД были непортируемыми на другие базы данных, и зачастую лингвистическое ядро не отделялось от предметно-ориентированных настроек.
Современные промышленные системы построения ЕЯ-интерфейсов (Franz 1998) обладают достаточно высокой степенью портируемости, что, безусловно, снижает стоимость построения ЕЯ-интерфейса. Лингвистическое ядро является универсальным элементом, словарь содержит универсальную лексику, используемую во многих ЕЯ-интерфейсах, модели предметной области могут содержать шаблоны, общие для нескольких предметных областей и т.д. Зачастую используется метафора "фабрики и изделия", изделием выступает ЕЯ-интерфейс, который собирается из готовых компонентов, которые настраиваются под конкретную базу данных.
Следует отметить, однако, что вопрос портирования на другие языки является открытым. Подавляющее большинство исследований проведено для английского языка, некоторые особенности которого изначально заложили в пути исследований мину замедленного действия - первоначально огромное количество усилий были потрачены на анализ синтаксиса. Сейчас можно сказать, что эти усилия не оправдали себя (Нариньяни 1997).
На стоимость ЕЯИ влияет также необходимая квалификация настройщика ЕЯ-интерфейса. Для систем, требующих навыков лингвиста, стоимость построения ЕЯИ больше, чем для систем, где для построения интерфейса требуется просто описать предметную область по некоторым предопределенным шаблонам и отобразить ее на схему базы данных, и дело здесь не только в стоимости труда лингвиста и инженера знаний или специалиста в области баз данных. Системы, требующие подстроек на уровне лингвистического ядра, являются более гибкими, поскольку позволяют разрешать проблемы понимания ЕЯ-запросов написанием соответствующих "заплаток", однако работы по написанию таких "заплаток" являются настолько сложными, требуют такого уровня понимания принципов машинного анализа ЕЯ в целом, что настройка ЕЯИ на уровне лингвистического процессора зачастую возможна только авторами системы построения ЕЯИ. Впрочем, сложность подстройки ядра очень сильно зависит от принципов анализа, используемого при написании инструментария, открытости ядра и т.д.
Коснемся теперь характеристики, присущей системам построения ЕЯ-интерфейсов - портируемость. В (Androutsopoulos et al 1995) вводится несколько видов портируемости:
- на другую предметную область,
- на другой язык,
- на другую СУБД,
- на другие платформы и языки программирования.
Портируемость на другую ПО. Обычно, если ЕЯ-интерфейс портируется на другую предметную область, систему необходимо "научить" словам и концептам, используемым в новой предметной области. Также надо отобразить МПО и МБД. Портируемость на другую предметную область может проводиться различными специалистами, и механизмы портирования могут быть ориентированы на:
- программиста: в некоторых системах часть кода (обычно небольшая и четко определенная) должна быть переписана;
- инженера знаний: конфигурация системы без программирования, построением схем предметной области и/или введением и описанием новых концептов ПО;
- администратора СУБД: БД-центрическое описание предметной области, например, описание некоторых важных для ПО ЕЯИ характеристик для каждой таблицы и поля БД;
- конечного пользователя: в предположении, что настройка ЕЯИ - постоянный процесс, ЕЯ снабжается средствами для настройки методом введения определений концептов на уровне ЕЯ и другими пригодными для конечного пользователя методами.
Портируемость на другой естественный язык. Подавляющее большинство ЕЯ-интерфейсов к БД были разработаны для английского языка. Переориентация ЕЯИ на другой язык является для большинства систем большой проблемой, вследствие активного использования законов языка на уровне морфологии, синтаксиса, существенно отличающихся от языка к языку. Иногда настройка на язык возможна переписыванием синтаксических и семантических правил, а также новым наполнением словаря. В описываемой работе переносимость на другой язык является достаточно высокой, что обусловлено использованием преимущественно семантической информации при анализе.
Портируемость на другую СУБД. Система является портируемой на другую СУБД, если она позволяет перенос ЕЯ-интерфейса на другую СУБД. В случае, если ЕЯИ генерирует запросы в распространенном языке (например SQL), он может быть легко портирован на другую СУБД, если она поддерживает этот язык. Если язык запросов ЕЯИ не поддерживается новой СУБД, ЕЯИ может быть портирован переписыванием компонента генерации формального языка, однако это справедливо только для систем, в архитектуру которых включен промежуточный уровень запроса. В противном случае для портирования необходимо существенно переписать ЕЯИ.
Портируемость на другую платформу. Некоторые ЕЯИ могли исполняться только на дорогих исследовательских машинах, используемых экзотические языки программирования (например, Lisp-машины), что делает их практически неприменимыми в реальных приложениях. В последнее время появление недорогих мощных компьютеров и повсеместная доступность таких языков, ориентированных на приложения искусственного интеллекта, как Lisp и Prolog, делают доступными и ЕЯИ, написанными на этих языках.
Кратко рассмотрим основные части ЕЯ-интерфейсов и их взаимосвязи. Прежде всего следует выделить из интерфейса анализатор ЕЯ как компонент, реализующий тот или иной метод анализа естественного языка, и от принципов построения которого зависит архитектура системы и основные характеристики интерфейсов на основе данного компонента.
Работа анализатора заключается в построении внутреннего представления входного ЕЯ-текста либо запроса, обычно в виде некоторой структуры, например, синтаксического дерева, семантической сети, фреймовой структуры и т.д. Предшествующим этапом для процесса анализа является лексический анализ (преданализ), который преобразует входной текст как последовательность символов, в цепочку лексем, поступающей на вход анализатора.
Необходимым компонентом работы анализатора является словарь, который содержит слова и фразы, обычно с привязкой к ним определенной информации, связанной с семантикой, морфологией и т.д., в зависимости от подхода анализа ЕЯ. Еще одним важным компонентом многих систем является модель предметной области, структура которой варьируется в очень больших пределах от системы к системе.
Для построения запроса на формальном языке источника данных используется модель источника данных, отражающая основную структуру СИД, ее части, существенные для данного ЕЯИ.
Для перевода запроса из внутреннего представления системы в формальный язык источника данных предназначен процесс генерации формального запроса. Некоторые системы имеют также модуль синтеза ЕЯ, который может применяться для генерации естественно-языкового представления запроса, например, для верификации понимания запроса системой, а также для генерации уточняющих вопросов (Franz 1998).
Модель предметной области в некоторых системах (см. там же) дополняется базой знаний со средствами вывода новых знаний.
На рис. 1.1.5-1 приведены основные составляющие ЕЯИ и взаимосвязи между ними, представленные потоками данных.
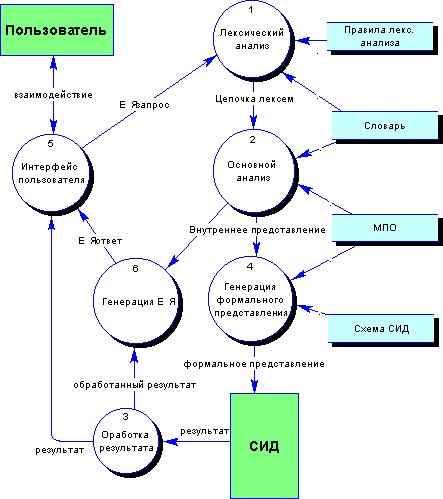
Рис. 1.1.5-1 Основные составляющие ЕЯ-интерфейсов и их взаимосвязи
1.2 Подходы к анализу ЕЯ-запросов к СИД
В данном разделе дается краткий обзор методов и подходов анализа ЕЯ применительно к теме построения ЕЯ-интерфейсов к структурированным источникам данных. Предпочтение при детальности рассмотрения отдавалось подходам, связанным с реляционными базами данных. Во многом это обусловлено обилием работающих систем, в т.ч. и коммерческих, осуществляющих ЕЯ-анализ с последующим обращением к базам данных.
1.2.1 Системы, основанные на шаблонах
Многие ранние ЕЯИ-системы были основаны на шаблонном подходе. Для примера рассмотрим таблицу базы данных, содержащую информацию о странах:
|
Country |
Capital |
Language |
|
France |
Paris |
French |
|
Italy |
Rome |
Italian |
|
... |
... |
... |
Простейшую основанную на шаблонах систему можно построить с помощью следующих правил:
Шаблон: ... "capital"... .<country>
Действие: Report Capital of row where Country = <country>
Шаблон: . . . "capital" . . ."country"
Действие: Report Capital and Country of each row
Согласно первому правилу, если ЕЯ-запрос содержит слово "capital" перед названием страны (т.е. значением поля Country), то система найдет записи, содержащие это название страны, и выведет соответствующую столицу. Например, для запроса "What is the capital of Italy?" будет использовано первое правило, и ответ будет "Rome". То же самое правило применится для запроса "Print the capital of Italy.", "Could you please tell me what is the capital of Italy?", и т.д. Во всех этих случаях ответ будет одинаковым.
В соответствии со вторым правилом, любой ЕЯ-запрос, в котором слово "capital" предшествует слову "country", вернет столицу каждой страны в соотвествии с содержимым таблицы. Так, запросы "What is the capital of each country?", "List the capital of every country.", "Capital and country please." будут подходить под второе правило.
Главным достоинством шаблонного подхода является его простота - здесь отсутствуют сложные модули синтаксического разбора (парсинга) и интерпретации, такую систему, основанную на шаблонах, легко реализовать. Однако простота подхода имеет оборотную сторону - такие системы сложно портировать, и их надежность понимания запросов оставляет желать лучшего.
В результате парсинга (синтаксического анализа) запроса в данном подходе дерево синтаксического разбора непосредственно отображается в выражение на языке запросов к базе данных. Типичная система, основанная на синтаксическом анализе - LUNAR (Woods 1972).
Синтаксически-ориентированные системы используют грамматику, описывающую возможные синтаксические структуры пользовательских запросов. Следующий пример показывает упрощенную грамматику систем наподобие LUNAR:
S à NP VP
NP à Det N
Det à "what" | "which"
N à "rock" | "specimen" | "magnesium" | "radiation" | "light"
VP à V N
V à "contains" | "emits"
Данная грамматика указывает на то, что предложение (S) состоит из группы подлежащего (NP), следующего за группой сказуемого (VP), группа сказуемого состоит из детерминанта (Det), следующего за подлежащим, детерминантом может быть "what" или "which", и т.д. Используя эту грамматику, ЕЯИ строит синтаксическую структуру запроса "which rock contains magnesium", показанную на (Рис. 1.2.1-1). ЕЯИ может затем отобразить дерево синтаксического разбора в следующий запрос к базе данных (X - переменная):
(for_every X (is_rock X)
(contains X magnesium) ;
(printout X))
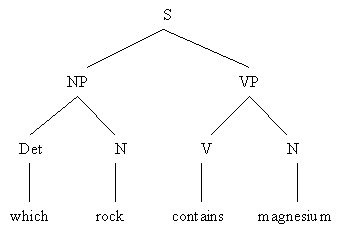
Рис. 1.2.1-1 Дерево синтаксического разбора
Отображение дерева в выражение запроса производится с помощью правил, и целиком основывается на синтаксической информации дерева разбора. Правила отображения могут быть следующими:
- "which" отображается в for every X.
- "rock" отображается в (is rock X).
- NP отображается в Det' N' , где Det' и N' являются отображениями детерминантов м подлежащего соответственно. Таким образом, отображение поддерева NP в нашем примере будет for every X (is rock X).
- "contains" отображается в contains.
- "magnesium" отображается в magnesium.
- VP отображается в (V ' X N'), где V ' является отображением сказуемого, а N' является отображением соответствующего подлежащего. Таким образом, поддерево VP отображается в (contains X magnesium).
- S отображается в (NP' VP' ; (printout X)), где NP' , VP' являются отображением поддеревьев NP and VP соответственно.
Обычно трудно составить систему правил, трансформирующих дерево разбора напрямую в некоторое выражение на языке запросов к реальным базам данных (например, SQL), поэтому данный подход применятся в основном в комбинации с другими.
В системах семантической грамматики ответ на ЕЯ-запрос также делается разбором запроса и отображением дерева в выражение на формальном языке. Отличие в том, что грамматические категории не обязательно соответствуют синтаксическим концептам. На Рис. 1.2.3-1 показана возможная семантическая грамматика.
S à Specimen question | Spacecraft question
Specimen question à Specimen Emits info | Specimen Contains info
Specimen à "which rock" | "which specimen"
Emits info à "emits" Radiation
Radiation à "radiation" | "light"
Contains info à "contains" Substance
Substance à "magnesium" | "calcium"
Spacecraft question à Spacecraft Depart info | Spacecraft Arrive info
Spacecraft à "which vessel" | "which spacecraft"
Depart info à "was launched on" Date | "departed on" Date
Arrive info à "returns on" Date | "arrives on" Date
Рис. 1.2.3-1 Семантическая грамматика
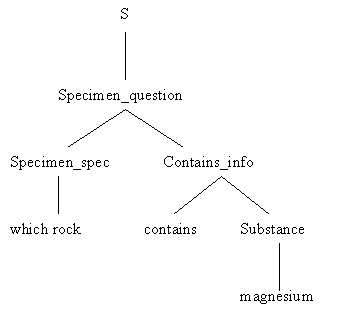
Рис. 1.2.3-2 Дерево разбора в семантической грамматике
Заметим, что некоторые категории грамматики на Рис. 1.2.3-1 (Substance, Radiation, Specimen_question) не соответствуют синтаксическим конструкциям (группе подлежащего, подлежащему, предложению). Семантическая информация о предметной области жестко привязана к семантической грамматике. Категории семантической грамматики обычно выбираются так, чтобы усилить семантические ограничения. Например, приведенная грамматика не допускает следования слова "light" после "contains" (синтаксически же эта фраза корректна - "contains light").
Грамматические категории могут быть выбраны также таким образом, чтобы облегчить отображение дерева запроса в запрос к базе данных. Семантическая грамматика была введена как инженерная методология, позволяющая просто включать семантические знания в систему. Однако, поскольку семантическая грамматика содержится жестко привязанные знания о конкретной предметной области, системы, основанные на этом подходе трудно потируются на другие предметные области - каждая ПО требует своей грамматики. Например, приведенная выше грамматика абсолютно неприменима для ЕЯ-интерфейса к кадровой базе данных.
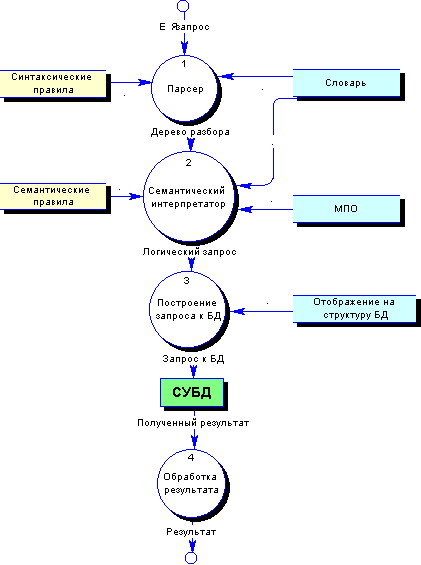
Рис. 1.2.4-1 Возможная архитектура системы с промежуточным языком запросов
Многие современные ЕИЯ к базам данных сначала преобразуют ЕЯ-запрос в логический запрос на некотором промежуточном языке представления. Промежуточный логический запрос выражает значение запроса в терминах модели предметной области, независимой от структуры базы данных. Затем логический запрос преобразуется в запрос на языке запросов к базе данных, этот запрос исполняется в базе данных. Многие современные ЕЯ-интерфейсы к БД используют не один, а несколько промежуточных языков запросов (Fox 1995).
На Рис. 1.2.4-1 показана возможная архитектура системы с промежуточным языком запросов. ЕЯ-запрос сначала обрабатывается синтаксически парсером. Парсер использует набор синтаксических правил для построения дерева синтаксического разбора, аналогичного показанному на Рис. 1.2.1-1. Семантический интерпретатор последовательно трансформирует дерево синтаксического разбора в язык промежуточного представления, используя семантические правила, рассмотренные ранее.
Семантически-ориентированный метод анализа ЕЯ-запросов был предложен А.С.Нариньяни (Нариньяни 1979). Далее он зарекомендовал себя как надежный метод понимания ЕЯ в ограниченных регистрах естественного языка. Этот метод использует закономерности выражения семантики в естественном языке. На основе данного метода созданы экспериментальные системы анализа ЕЯ в таких регистрах, как запросы к базам данных, короткие тексты в узких предметных областях, среди них - медицинские тексты описания рентгенограмм и УЗИ (Кононенко 1994, Сосенская 1997), телеграммы метеосводок (Загорулько 1999). На основе данного подхода в начале 90-х годов была сделана система построения ЕЯ-интерфейсов к dBASE-совместимым базам данных InterBASE (Trapeznikov et al 1993).
Остановимся на данном подходе более подробно.
Суть данного метода заключается в оперировании т.н. компонентами, являющимися концептами, имеющими смысл в достаточно узком регистре ЕЯ (в данном случае - регистр запросов к СИД). Компоненты образуют семиотическую систему, а процесс анализа представляет собой процесс "снизу-вверх", при котором на основе компонентов входной цепочки (например, Отрицание, Отношение, Атрибут, Значение) образуются вторичные компоненты, имеющие, например, семантику предикатов, логических операций и т.д. Поскольку система компонентов мало зависит от конкретного естественного языка, данный метод позволяет построение достаточно универсальных лингвистических процессоров.
Система компонентов дополняется структурой ориентаций (ОР-структурой), которая представляет собой в общем случае ориентированный граф, моделирующий предметную область и ее отображение на схему СИД. Вершинами этого графа являются значения признака ориентации, дуги соответствуют отношению "общее-частное". Комбинация системы компонентов и ориентаций заключается в приписывании лексемам определенного компонента (семантического класса) и ориентации на некоторые вершины графа. Процесс анализа использует ориентации для устранения неоднозначности а также для сборки из исходных компонентов других по определенным правилам.
На рис. 1.2.5-1 приведена возможная структурная схема системы, основанной на семантически-ориентированном подходе. Данная схема отражает структуру системы, как симбиоза среды для построения (настройки) ЕЯ-интерфейсов и собственно ЕЯ-интерфейса. Выделены два класса средств с ситемой - средства настройки, используемые настройщиком через монитор настройщика, и средства исполнения ЕЯИ, с которыми работает "наивный" пользователь через монитор пользователя.
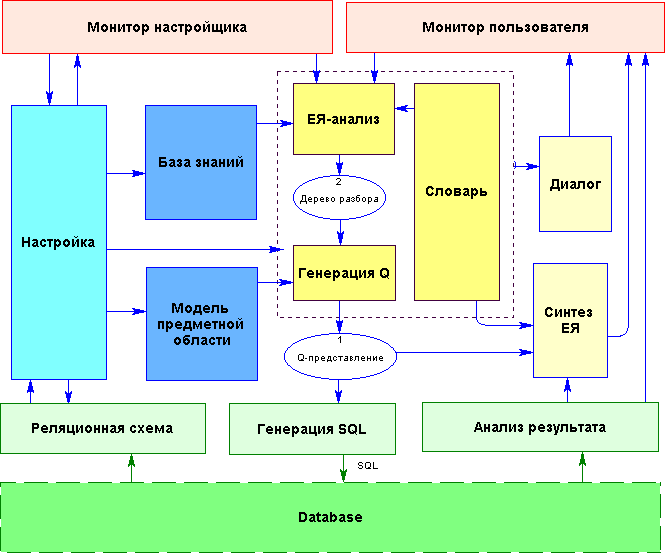 Рис. 1.2.5-1 Структурная схема
системы, основанной на семантически-ориентированном подходе
Рис. 1.2.5-1 Структурная схема
системы, основанной на семантически-ориентированном подходе
Модель предметной области является одной из важнейших составляющих понимания ЕЯ, заслуживающей отдельного рассмотрения. Пользователь, обращаясь с запросом к информационной системе, как правило, имеет некоторое представление о предметной области, в которой работает информационная система. В то же время сама система (речь идет в данном случае об ИС вообще, а не только о ЕЯ-интерфейсах) представляет только некоторое подмножество этой предметной области. От того, насколько полно и точно отражена эта предметная область в системе, зависит качество ее работы и удобство работы с ней.
1.3.1 Соотношения знаний о языке и знаний о предметной области в ЕЯ-интерфейсе
Адекватность описания МПО в ЕЯ-интерфейсах напрямую влияет на качество работы ЕЯИ. ЕЯ-запрос отражает феномены как языка, так и предметной области, причем эти феномены тесно взаимосвязаны. Анализ ЕЯ должен использовать знания о конкретном языке, т.е. лингвистические знания, а также знания о конкретной предметной области. Отделение одного от другого позволяет облегчить перенос системы анализа ЕЯ на другой язык и/или на другую предметную область. Шенк в (Шенк 1979) указывает на то, что, представление человека о некоторой предметной области можно описать структурами, инвариантными по отношению к языку. Эти структуры, названные им концептуальными структурами (КС), могут иметь непосредственное отражение в одном языке и не иметь его в другом. От модели предметной области, таким образом, требуется отражение ПО независимо от естественного языка.
В (Sharoff, Zhigalov 1999) представлена методология отделения предметной области от регистра запросов к базам данных в ЕЯ-интерфейсах. Эта методология заключается в основании анализа на наборе семантических компонентов, отражающих семантику определенного регистра (жанра) естественного языка - обращение с запросом к базе данных и основана на семантически-ориентированном подходе. Под регистром понимается семиотическая система компонентов их значений в определенной области применения естественного языка. МПО строится на основе ER-диаграмм и отражает представление предметной области в виде схемы классов и отношений между ними.
1.3.2 Предметная область и ее отражение в структуре и содержимом источников данных
Модель предметной области (МПО) представляет собой систему средств для отражения тех сущностей, объектов, действий реального мира, которые отображены данной ИС. Проектирование любой базы данных следует начинать именно с описания ее на концептуальном уровне - то есть построения модели предметной области базы (Цаленко 1989).
Говоря о ЕЯ-интерфейсах к СИД, следует упомянуть одну особенность построения ЕЯ-интерфейсов к СИД. Как правило, настройщик ЕЯ-интерфейса не имеет возможности перепроектировать целевую базу данных. Кроме того, опыт показывает, что базы данных зачастую даются "as is", без формального описания предметной области. И если схему источника данных на логическом уровне нетрудно восстановить автоматически из самого источника, то автоматически восстановить концептуальную модель базы из логической обычно невозможно. Причины этого в том, что концептуальный уровень представления данных выше логического, и при построении логической схемы базы данных часть информации из концептуальной схемы "повисает в воздухе", то есть не имеет явного отражения в схеме. Например, сущности в диаграмме сущность-связь могут быть связаны как 1:1 или 1:n, что отражается явно в диаграмме. Однако в реляционной схеме размерность связи не указывается, таким образом, при переходе к реляционной схеме от ER-диаграммы теряется важная концептуальная информация о предметной области.
Отображение МПО на структурную схему СИД является необходимой составляющей для ЕЯ-интерфейсов, построенных по архитектуре с промежуточным уровнем представления запроса. Это отображение призвано учесть все особенности строения СИД, имеющие отношение к ПО, и по возможности скрыть те особенности строения, которые имеют "техническую" природу. Так, реляционная схема РСУБД, как правило, отражает диаграмму сущность-связь данной предметной области, однако с неизбежностью привносит некоторые особенности, характерные для реляционного подхода, и лишние на концептуальном уровне (например, числовые идентификаторы объектов, обычно не несущие самостоятельной информации). Как правило, чем выше уровень нормализации реляционной базы данных, тем легче выделить структуру ПО из схемы базы.
Многие элементы ПО не имеют непосредственного отражения в структуре, но могут быть получены анализом содержимого СИД. Особенно это проявляется в слабо нормализованных базах данных, когда в полях таблиц хранятся повторяющиеся элементы (например, названия стран, фамилии сотрудников), вместо хранения уникальных идентификаторов. В этом случае могут быть предприняты усилия по псевдо-нормализации базы данных и выделения новых сущностей уже на уровне МПО (например, выделением стран и сотрудников в отдельные сущности).
1.3.3 Расширения и ограничения как метод задания элементов МПО
Необходимо заметить, что предметная область представлена в СИД, как правило, частично и с некоторыми ограничениями. Например, если в базе данных о клиентах есть поле, которое содержит названия стран, совсем не обязательно, что база будет содержать исчерпывающий список стран. Таким образом, база данных содержит подмножество элементов, входящих в состав данной предметной области.
Эта ограниченность представления ПО в СИД может быть скомпенсирована за счет расширения модели ПО в ЕЯ-интерфейсе по отношению к содержимому СИД. Это означает, что пользователь, спросив о стране, не представленной в базе, сможет получить достаточно интеллигентный ответ "Указанная страна в базе данных отсутствует", вместо выдачи названия страны как не понятого системой слова. Безусловно, расширение МПО стандартными множествами способствует лучшему пониманию ЕЯ-запросов, поскольку приводит к расширению словаря лексикой данной ПО, а, значит, и к повышению надежности анализа.
Введением в МПО расширенных стандартных множеств элементов предметной области можно компенсировать далеко не все потребности в расширенной МПО в ЕЯИ. В (Нариньяни 1979) приведены варианты снабжения МПО сведениями о регулярных выражениях, или кодах. Примеры кодов: телефоны, email-адреса, и другие открытые множества значений, которые выражаются регулярными выражениями. Кодами считаются также обозначения закрытых множеств, которые имеют однотипную кодировку, и которые удобнее задавать регулярными выражениями: марки автомобилей, самолетов и т.д. Там же предложено использовать коды еще на этапе лексического анализа. Модель предметной области, таким образом, содержит шаблоны для кодов, с указанием семантической ориентации для каждого шаблона.
Аналогичным образом может быть задано ограничение значений атрибутов МПО по отношению к области значений полей базы данных, заданных их типом. Например, год приема на работу сотрудника в кадровой базе не может быть меньше некоторого минимального значения (например, даты создания организации), и не может быть больше текущей даты. Тот же принцип применим для многих числовых полей. Причем значимым может быть не только само значение, но также его тип, точность его представления, единица измерений. Например, возраст сотрудника - целое число от 18 до 70, диаметр винта - вещественное число от 2 до 30, с шагом 0.5, выражено в миллиметрах. Также допустимо использование шкал значений.
Таким образом, в состав модели предметной области в общем случае входит часть, описывающая структуру ПО, например, ER-диаграммой (см. далее), а также часть, описывающая ПО с содержательной стороны - например, множества объектов, значений и т.д. Обе эти части имеют соответствие, а зачастую и источники в самом СИД (Рис. 1.3.3-1).
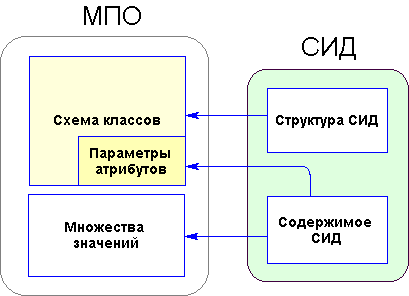
Рис. 1.3.3-1 Соотношение частей МПО структуре и содержимому СИД
1.3.4 Средства описания концептуальной схемы источника данных
При рассмотрении свойств различных типов СИД мы рассматривали их структурные элементы. Очевидно, удобство отображения структурных элементов различных СИД на структуру МПО - весьма важный параметр, который должен быть учтен при выборе средств описания ПО. Далее рассматриваются некоторые типичные способы описания МПО, а также возможные способы отображения этих средств на схему различных типов СИД.
Семантические сети являются универсальным методом представления знаний, в частности, знаний о предметной области. В этом представлении узлы представляют объекты или концепты, а дуги - связи или ассоциации. Связи могут быть специфичны для предметной области либо независимы от ПО.
Наиболее частое решение использования СС - качестве узлов используются конкретные объекты, в качестве связей - отношения между ними. Так, в системе SemP-F (SemP-F 1997) используется семантическая сеть вместе с механизмом недоопределенности. В качестве узлов сети выступают объекты некоторых классов. Объекты, помимо значений своих атрибутов (слотов), которые могут быть недоопределенными, имеют ограничения, заданные как выражения над значениями слотов данного объекта. Ограничения также могут быть заданы для отношений, в этом случае выражение для ограничения включает слоты связываемых объектов. Отношения также являются объектами некоторых классов.
В (Sharoff 1993) представлено решение использования объектно-ориентированной сети для представления лингвистической информации в среде SNOOP (System with Network and Object-Oriented Programming). Несмотря на то, что система имеет направленность на создание лингвистических процессоров, она имеет достаточно универсальное сетевое представление, которое может быть использовано в других задачах, например, моделирование предметной области.
Инструменты для работы с сетевыми представлениями включают, как правило, механизмы для навигации по сети. В SemP-F и SNOOP применяется продукционный механизм с возможностью объединения продукционных правил в группы. SemP-F, помимо этого, имеет еще и механизм разрешения противоречий с помощью альтернатив, включающий в себя механизм отката (бэктрекинга).
В применении моделирования ПО СИД следует заметить, что моделированию, как правило, подвергаются не отдельные объекты, как в Semp-F, а классы объектов и отношений между ними.
Фреймы являются структурами представления знаний, отражающие стереотипную информацию об объектах (Minsky 1975). Фрейм представляет собой структуру, имеющую заголовок и определенный набор слотов. Значением слота, помимо простого значения, может быть другой фрейм. В целом можно сказать, что фреймы расширяют сетевое представление, включая структурированность и иерархию.
Рассмотренная в предыдущем пункте система SemP-F также использует концепцию фреймов, позволяя в качестве значения слотов объекта задавать другой объект.
Диаграммы сущность-связь (Entity-Relationship Diagramm, в дальнейшем - ER-диаграммы) были введены Ченом (Chen 1976) как средство для описания предметных областей. Сейчас под эту модель подходят несколько родственных формализмов, используемых для проектирования информационных систем и баз данных на концептуальном уровне. Диаграммы сущность-связь описывают предметную область в аспекте выделения классов объектов и отношений между объектами.
В ER-диаграммах центральными составляющими элементами выступают сущности и связи. Сущность имеет некоторое имя и представляет один из типов объектов предметной области. Сущность может иметь атрибуты, каждый атрибут имеет название и некоторый тип. Связи являются бинарными и снабжены параметрами. Среди параметров - размерность связи, обозначающая, сколько объектов одного класса может быть ассоциировано с объектом другого класса: примерами размерности могут быть 1:1, 1:n и т.д. Еще одним параметром является опциональность связи. Помимо параметров, связь может иметь два имени - по направлению связи (связи двунаправлены). Для примера приведем ERD рассматриваемой далее базы данных "North Wind", представляющей типичную корпоративную базу данных средней сложности (Рис. 1.3.4-1):
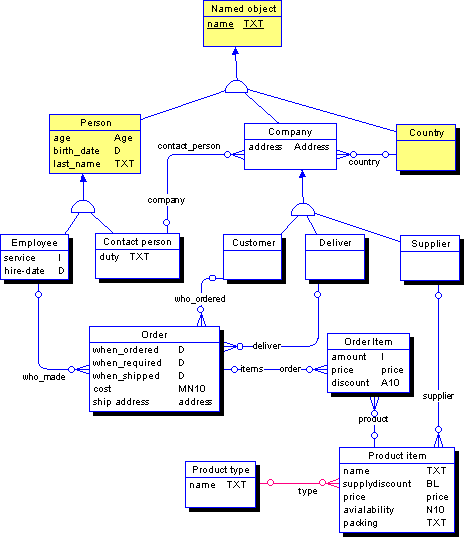
Рис. 1.3.4-1 Диаграмма сущность-связь базы данных "North Wind"
В этой схеме сущности Employee и Contact Person наследуются от абстрактной сущности Person, а Company является общим предком для Customer, Deliver, Supplier. Person, Company и Country наследуют абстрактную сущность Named Object, которая обозначает все объекты, денотируемые по имени.
По своему строению ER-диаграммы являются разновидностям семантических сетей, с сущностями в качестве узлов сети. Кроме того, они наследуют объектно-ориентированный подход, и некоторые реализации ERD позволяют использовать наследование между сущностями, в точности соответствующее наследованию между классами в ООП (Буч 1992).
Появившийся в 1998 году и утвержденный в качестве рекомендации консорциума W3C язык описания ресурсов Resource Description Framework (RDF) (RDF Specification 1999) уже получил признание многих ведущих компаний-разработчиков ПО и поставщиков интернет-ресурсов.
Этот язык использует XML-синтаксис (XML, 1998). Он описывает ресурсы в виде ориентированного размеченного графа – каждый ресурс может иметь свойства, которые в свою очередь также могут быть ресурсами или их коллекциями.
Под ресурсом традиционно понимается некоторый документ или набор документов в Сети, представленный своим URL, например, http://www.rriai.org.ru/. Например, для ресурса можно задать свойства "заголовок", "описание", "авторство", причем для "авторства" как ресурса могут быть заданы "имя", "фамилия" и "e-mail", как свойства (Рис. 1.3.4-2, Рис. 1.3.4-3).
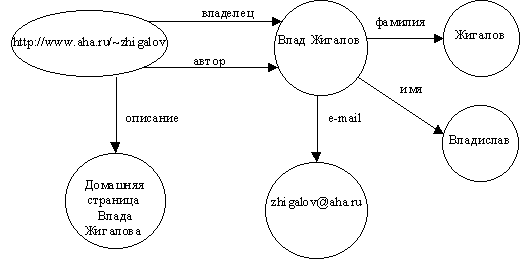
Рис. 1.3.4-2 Представление метаинформации о ресурсе в нотации RDF
<rdf:RDF>
<rdf:Description about="http://www.aha.ru/~zhigalov">
<x:owner ID="Влад_Жигалов"/>
<x:autor ID="Влад_Жигалов"/>
<x:description>Домашняя страница
Влада Жигалова
</x:description>
</rdf:Description>
<rdf:Description ID="Влад_Жигалов">
<x:name>Влад</x:name>
<x:lastname>Жигалов</x:lastname>
<x:email>zhigalov@aha.ru</x:email>
</rdf:Description>
</rdf:RDF>
Рис. 1.3.4-3 Представление метаинформации о ресурсе в синтаксисе RDF
Описание с помощью RDF не ограничивается только описанием документов Интернет. Этот стандарт достаточно универсален и гибок для того, чтобы описывать многие типы структурированных данных. Например, в RDF естественно выражаются диаграммы сущность-связь. Описание семантики ресурса на RDF может быть как “внешним”, когда описывается ресурс в целом, так и “внутренним”, когда описывается внутренняя структура ресурса – будь то база данных, XML-документ, или целый сайт.
Важной особенностью стандарта RDF, как и лежащего в его основе XML, является расширяемость. На RDF же можно задать структуру описания источника, используя и расширяя встроенные понятия RDF-схем, такие как классы, свойства, типы, коллекции. Модель схемы RDF включает наследование; наследоваться могут классы и свойства.
Помимо описания структуры, RDF позволяет оперировать утверждениями. Выражение “ресурс R1 в качестве свойства P имеет ресурс R2” можно проинтерпретировать и как предикат P(R1, R2), а затем использовать это утверждение как объект других утверждений. Такая интерпретация позволяет описывать с помощью RDF концептуальную информацию.
Таким образом, RDF вполне подходит на роль универсального языка описания семантики ресурсов и взаимосвязей между ними.
В данном разделе рассматриваются несколько типов структурированных источников данных - реляционные и объектные СУБД, XML, RDF. Первые два типа относятся к наиболее распространенным источникам в настоящий момент. Последние два можно отнести к бурно развивающемуся сектору СИД - Интернет-хранилищ. Для Интернет-хранилищ характерна меньшая степень структуризации, чем для баз данных. Степень структуризации данных в XML-документах варьируется достаточно сильно. Имеет смысл говорить об XML-документах как о классе СИД, объединяющем несколько типов. Так, HTML-документы (HTML 4.0), которые с некоторыми допущениями можно также включить в этот класс, стоят на одном конце шкалы степени структуризации - достаточно слабой, на другом конце можно поставить такой стандарт как XML-Data (XML-Data 1998), являющийся аналогом реляционных баз в XML-нотации, и обладающим высокой степенью структурированности. Для последнего рассматриваемого типа - RDF применим скорее термин метаданные - RDF изначально создавался для описания ресурсов целиком, без раскрытия внутренней структуры ресурса. Однако этот стандарт описания ресурсов является расширяемым, кроме того, он прекрасно ложится в класс СИД, к которым можно строить ЕЯИ. Это обусловило достаточно подробное описание RDF в разделе, описывающем средства описания модели предметной области.
Такая ограниченность обозрения типов СИД (два типа - для баз даных, и два - для Интернет-хранилищ) обусловлено относительно низкой степенью распространения других типов СИД (иерархические, сетевые базы данных, SGML) в современных промышленных информационных. По иным причинам в обзор не попали такие распространенные источники (хранилища) данных, как электронные таблицы, поскольку, строго говоря, они не являются структурированными, в силу того, что у электронных таблиц отсутствует схема данных, являющаяся обязательным атрибутом СИД.
Еще одним важным критерием для типов СИД, которые попали в рассмотрение, является наличие универсального языка запросов к СИД данного типа. Эти языки рассматриваются в п 1.5.
Существенным для данного обзора типов СИД является их структура и составные элементы этой структуры. Такое акцентирование внимания обусловлено необходимостью отображения схемы СИД на модель предметной области ЕЯ-интерфейса.
Реляционные СУБД (РСУБД) являются в настоящее время самым распространенным типом структурированных источников данных. Это во многом обусловлено существованием единого стандарта на язык структурированных запросов SQL (последней редацией которого в настоящее время является стандарт SQL92). SQL, помимо стандартизации собственно команд запросов и операций, манипулирующих содержимым баз данных - добавление, удаление и изменение записей (DML - Data Manipulation Language), определяет операции по заданию строения РСУБД в виде реляционной схемы (DDL - Data Definition Language),
Так, создание некоторой таблицы Employees на языке SQL записывается следующим образом:
Create table Employees
(
EmployeeID INTEGER not null,
LastName VARCHAR(20) not null,
FirstName VARCHAR(10) not
null,
BirthDate TIMESTAMP null,
HireDate TIMESTAMP null,
Address
VARCHAR(60) null,
HomePhone VARCHAR(24) null
)
Реляционные СУБД обычно включают в себя следующие основные структурные элементы:
- сервер
- базы данных
- таблицы
- ограничения (constraint)
- хранимые запросы (view)
- поля
- записи
- индексы
- ключи
Сервер - программно-аппаратная система, обслуживающая операции над базами данных. На сервер возлагаются задачи по поддержанию целостности данных, транзакционности операций, а также администрирования и безопасности источников - баз данных. Во многих простых СУБД сервер как таковой отсутствует, а его задачи выполняют драйверы доступа к данным. В этом случае, как правило, транзакционность и целостность этими драйверами не поддерживается, и эта задача возлагается на прикладную программу.
База данных является обычно самым общим структурным элементом с точки зрения хранимых данных. Таблицы и виды, а также хранимые процедуры, ключи и индексы должны иметь уникальные имена в пределах одной базы. Как правило, базы данных являются полностью автономными с точки зрения хранящихся в них данных, то есть для работы с данной базой не нужно иметь доступ к другим базам. Однако из этого есть исключения - так, MS SQL Server позволяет в пределах одной SQL-команды обращаться к элементам других баз, работающих на одном сервере с данной.
Таблица реляционной СУБД является центральным элементом в этом типе СИД. Таблица представляет собой набор кортежей с одинаковой структурой. Эти кортежи называются записями, а названия элементов структуры - полями таблицы. Поля не могут быть сложного типа, иными словами, одно поле не может состоять из других полей. Типы полей для данного вида РСУБД являются предопределенными. Традиционными типами полей являются строковый, числовой, дата. Таблицы могут иметь произвольное число записей, количество полей в одной таблице обычно ограничено.
Хранимые запросы, или виды (View) представляют собой "виртуальные таблицы", структура и наполнение которых определяется SQL-запросом. View могут участвовать в запросах наравне с другими таблицами, но для операций DML налагается ряд условий на строение view, точнее, на строение SQL-запроса SELECT, лежащего в его основе.
Индексы и ключи являются внутренними элементами баз данных, их строение, как правило, недоступно программам "извне". Индексы повышают скорость работы при операциях поиска/выборки. Ключи представляют собой индексы особого назначения - они играют важную роль при обеспечении целостности данных. Первичные ключи предназначены для обеспечения уникальности значений поля или набора полей таблицы, вторичные ключи - для обеспечения ссылочной целостности.
Немаловажной причиной распространения РСУБД, особенно в промышленных системах является обеспечение целостности данных самими СУБД. Это позволяет прикладным задачам полагаться на гарантированную внутреннюю логическую непротиворечивость источников данных. Например, если в таблице, являющаяся родительской по отношению к данной, делается попытка удалить некоторую запись, автоматически проверяется наличие связанных записей в данной таблице, и в случае, если эти записи есть, удаление производиться не будет - сервер возвратит код ошибки.
Целостность данных осуществляется с помощью т.н. ограничений - constraints. Ограничения определяют зависимости между таблицами по определенным полям. В реляционной схеме эти ограничения обозначаются реляционными связями. Например, для того, чтобы определить реляционную связь между таблицей Employees и таблицей Orders, являющейся дочерней по отношению к первой, следует определить структуру таблицы Orders следующим образом:
CREATE TABLE Orders (
OrderID int NOT NULL ,
CustomerID nchar (5) NULL ,
EmployeeID int NULL ,
OrderDate datetime NULL ,
CONSTRAINT PK_Orders PRIMARY KEY
(
OrderID
),
CONSTRAINT FK_Orders_Employees FOREIGN KEY
(
EmployeeID
) REFERENCES Employees (
EmployeeID
)
)
В этом примере ограничение FK_Orders_Employees определяет реляционную связь между двумя таблицами и требует, чтобы значения поля EmployeeID в таблице Orders обязательно присутствовало в таблице Employees в одноименном поле (то есть заказ всегда должен иметь сотрудника, этот заказ обслужившего).
Поддержание целостности данных включает также задачу отслеживания уникальности первичных ключей. В приведенном выше примере поле OrderID в таблице должно быть уникальным - оно является уникальным номером заказа. Конструкция PRIMARY KEY задает такое правило, а также задает первичный ключ.
Первичные и вторичные ключи взаимосвязаны - вторичный ключ может ссылаться только на поле, являющееся первичным ключом во второй таблице.
Для того, чтобы с одним источником данных могло работать одновременно несколько прикладных задач, реляционные СУБД обладают механизмами блокировок и транзакций.
Блокировка - временное закрытие некоторого ресурса базы данных (таблицы, записи) для некоторых операций. Блокировка может возникнуть при совершении операции модификации некоторым процессом (блокирующий процесс), при этом другие процессы, пытающиеся модифицировать тот же ресурс, становятся заблокированы. Как только операция модификации завершается, ресурс разблокируется.
Транзакция - последовательность операции модификации в базе данных, который должен либо осуществиться полностью, либо не осуществиться вовсе. Примером могут служить финансовые транзакции. Например, при некоторой операции деньги снимаются с одного счета и кладутся на второй, при этом недопустимо совершение только половины этой операции (уменьшение суммы на первом счете без увеличения на втором).
Язык SQL определяет две операции управления транзакциями: завершение (COMMIT) и откат (ROLLBACK) транзакции. COMMIT подтверждает операции, сделанные ранее над базой данных со времени последнего COMMIT, ROLLBACK отменяет всю эту последовательность операций.
Реляционные базы данных явились большим шагом вперед по сравнению с иерархическими базами, основанными на сетевых и древовидных структурах (Мартин 1978). Эта прогрессивность заключается в более простом виде представления данных - в виде двумерных таблиц. Реляционный подход позволил подойти с формальной точки зрения на универсальные операции над данными, чему в значительной степени способствовала реляционная алгебра.
Однако простое преобразование формата данных из древовидных и сетевых структур в реляционные может привести к значительной избыточности данных. Чтобы устранить эту избыточность, Коддом были введены несколько нормальных форм, наследующих одна другую. Сам процесс устранения избыточности данных путем изменения структур базы называется нормализацией.
Первая нормальная форма
Любые данные, представленные в виде таблиц, считаются находящимися в первой нормальной форме. Нормализация здесь имеет место по сравнению с древовидными (иерархическими) структурами. Для реляционных же бах данных первая нормальная форма является исходной, наименее нормализованной формой.
Вторая нормальная форма
Таблица задана во второй нормальной форме, если она удовлетворяет требованиям первой нормальной формы, и каждое поле, не являющееся ключевым в этой таблице, полностью зависит от ключевых полей.
Третья нормальная форма
В ряде случаев и вторая нормальная форма порождает неудобства. Для их устранения используется последний шаг нормализации, преобразующий вторую нормальную форму в третью. На этом шаге ликвидируется так называемая транзитивная зависимость.
Третья нормальная форма определяется следующим образом: таблица задана в третьей нормальной форме, если она удовлетворяет второй нормальной форме и каждое поле, не являющееся ключевым, нетранзитивно зависит от ключевых полей.
Исследования в области объектных баз данных, исключительно активно развивавшиеся в прошлом десятилетии, привели в конце 80-х к образованию промышленных компаний и рынка систем управления объектными базами данных (СУОБД). Эти продукты довольно быстро приобрели черты зрелых СУБД, зарекомендовавших себя в ряде важных областей - таких как: САПР, промышленность программного обеспечения, географические информационные системы, финансовая сфера, медицинские применения, телекоммуникации, мультимедиа, управляющие информационные системы.
Объектные СУБД представляют собой попытку хранения структурированных данных способом, несколько отличным от реляционных СУБД. Согласно методологии СУОБД, при хранении информации, поиске и представлению ее прикладным задачам применяется объектно-ориентированный подход (ООП). Он заключается в том, что данные представлены в виде объектов и их свойств, а также связей между объектами. Пользователь (прикладная задача) избавлены от необходимости представления объектным данных в виде таблиц, что имеет место в реляционных СУБД.
Летом 1991 г. была образована Object Database Management Group (ODMG) - Группа Управления Объектными Базами Данных - как консорциум фирм-производителей СУОБД и других заинтересованных участников для разработки стандарта СУОБД. В конце 1993 г. группа завершила опубликованием Стандарт объектных баз данных ODMG-93 (ODMG 1993).
ODMG-93 определяет СУОБД как СУБД, интегрирующую свойства баз данных и объектно-ориентированных языков программирования. СУОБД обеспечивает представление объектов базы данных как объектов языка программирования по отношению к одному или к ряду языков программирования. СУОБД расширяет язык программирования средствами долговременного хранения объектов, управления конкурентным доступом, восстановления данных, объектных запросов и другими средствами систем баз данных.
Основные компоненты архитектуры
Объектная модель. Объектная модель OMG используется в качестве основы объектной модели ODMG-93. Объектная модель-ядро архитектуры OMG спроектирована в качестве "общего знаменателя" брокеров объектных заявок, объектных систем баз данных, объектных языков программирования и других применений. В согласии с архитектурой OMG, ODMG-93 конструирует профиль СУОБД для модели-ядра OMG, вводя дополнительные компоненты (такие как, например, связи (relationships)).
Язык определения объектов (ODL). Основой языка определения объектов ODL является язык определения интерфейсов IDL архитектуры OMG.
Язык объектных запросов (OQL). Определен декларативный язык запросов для обращения к объектным базам данных и их обновления. В качестве синтаксической основы OQL используется стандарт языка SQL-2, хотя OQL обладает более мощной семантикой. Вопрос о сближении OQL с разрабатываемым стандартом языка SQL-3 остается открытым.
Связывание с языками программирования. Особое внимание уделено наиболее важному в настоящее время языку для связывания с СУОБД - языку C++. Связывание с C++ основано на определении версии ODL на базе синтаксиса C++. Связывание включает механизм вызова OQL, процедуры и операции над базами данных и транзакциями. Связывание с C++ определяет способы написания мобильных программ на C++ для манипулирования долговременно хранимыми объектами, а также общие принципы связывания с языком Smalltalk. В дальнейшем предполагается определение связывания с другими языками программирования. Существенно, что не предполагается фиксировать некоторый универсальный синтаксис языка манипулирования данными: он зависит от языка программирования.
Структурные элементы
- сервер
- базы данных
- экстенты
- объекты
- атрибуты
- связи
Использование терминов сервер и база данных здесь полностью аналогично их использованию применительно к РСУБД. Остальные структурные элементы определяются объектной моделью, применяемой в СУОБД - ODMG-93.
Объектная модель ODMG-93
Используемая объектная модель ODMG-93 является расширением объектной модели OMG, а язык определения объектов - расширением языка IDL OMG.
Согласно объектной модели ODMG-93, каждый объект имеет определенный, единственный тип. Поведение объектов определяется операциями, заданными для объектов этого типа. Операции определяются своими сигнатурами. Состояние объекта определяется значениями его свойств. Свойства могут быть либо атрибутами объекта либо его связями с другими объектами. Свойства и операции составляют характеристики типа. Тип определяется одним интерфейсом, которому может соответствовать одна или большее число реализаций. Типы в свою очередь являются объектами и могут иметь собственные свойства из следующего жестко ограниченного набора:
supertype - типы образуют ациклический граф на основе отношения подтип/супертип. Все операции и свойства супертипа наследуются подтипом. Множественное наследование возможно. Подтип может уточнять свойства и операции супертипа и вводить новые свойства и операции;
extent - множество экземпляров данного типа в базе данных (экстент). С экстентом система связывает индекс для эффективного доступа к экземплярам типа. Если тип A является экземпляром типа B то экстент A является подмножеством экстента B.
key - в некоторых случаях экземпляры типа можно однозначно идентифицировать значениями заданного набора свойств объекта (атрибутов и/или связей). Такие свойства могут быть объявлены ключевыми для типа.
Допускается спецификация абстрактных типов, которые не могут иметь экземпляров. Их характеристики наследуются подтипами. Ниже дан пример спецификации типа на ODL.
Interface Course
{
extent courses;
keys name, number;
attribute string name;
attribute string number;
relationship
List<Section> has_sections;
relationship
Set<Course> has_perequisites
inverse
Course::is_perequisite_for;
relationship
Set<Course> is_perequisite_for
inverse
Course::has_perequisites;
offer(in Semester);
drop(in Semester)
}
Иерархия типов ODMG-93 имеет общую условную вершину, именуемую Denotable_Object (Обозначаемый объект). Различаются два основных подкласса типов обозначаемых объектов - изменчивые (mutable) и неизменчивые (immutable)2).
В стандарте этим типам соответствуют два разных термина, обозначающие их значения: объект (изменчивый) и литерал (неизменчивый). Объекты отличаются от литералов тем, что они существуют независимо от их значений благодаря уникальной идентифицируемости. Типы объектов и литералов наследуют предикат equal? из типа Denotable_Object, хотя семантика этой операции для объектов и литералов совершенно различна.
Итак, введены иерархии изменчивых и неизменчивых встроенных типов. В каждой иерархии различаются два подкласса типов: атомарные и структурированные. Важным атомарным типом объектов является тип Type - по существу, метатип, экземплярами которого являются любые типы. Атомарными литеральными типами являются традиционные скалярные типы целых, вещественных, символьных и логических литералов. Встроенными структурированными типами являются тип структуры (Structure) и типы коллекций - тип множества (Set), тип мультимножества (Bag), тип списка (List), тип массива (Array). Существенно, что структурированные типы объектов являются изменчивыми, а структурированные литеральные типы - неизменчивыми. Последние синтаксически так и объявляются, например Immutable_Set. Временные типы SQL-2 являются также встроенными литеральными подтипами типа Immutable_Structure.
Типы объектов могут быть объявлены как подтипы других типов объектов, например:
Associate_Professor: Professor{...}
В подтипах операции супертипов могут перекрываться. Операции над объектами типа могут иметь побочные эффекты. Объектная модель ODMG-93 является строго типизированной. Совместимость типов объектов определяется отношением подтипа, заданным на иерархии типов объектов.
На объектных типах определена операция create, создающая объект в памяти, присваивает ему уникальный идентификатор, который и возвращается в качестве результата операции. Наряду с идентификаторами, объекты могут иметь несколько имен, удобных программистам или конечным пользователям. Очевидно, имя должно однозначно идентифицировать объект в области действия имени.
Атрибуты объекта имеют своими значениями литералы.
Значения атрибутов инкапсулированы: доступ к ним реализуется встроенными операциями get_value, set_value. Атрибуты не являются "объектами первого класса": нельзя определить атрибуты атрибутов, связи между атрибутами, дополнительные операции на атрибутах.
Структуры и коллекции
Структуры имеют фиксированное число поименованных слотов, каждый из которых содержит объект или литерал соответствующих слотам типов. Коллекции содержат произвольное число элементов - экземпляров одного и того же типа - параметра типа коллекции. Полиморфизм коллекций достигается как обычно посредством иерархии типов. Коллекции могут быть упорядоченными и неупорядоченными. С колекциями могут быть связаны итераторы (экземпляры типа iterator), позволяющие фиксировать текущую позицию в коллекции для извлечения, помещения, модификации элементов коллекции в нужном порядке.
Структурированные объекты могут конструироваться произвольным образом - множества структур, структуры, включающие множества, и др.
Тип связи
Типы связей определяются между изменчивыми типами объектов. Поддерживаются бинарные связи вида 1:1, 1:n и n:m. Типу связи 1:n и n:m соответствует единственный экземпляр типа. Вместе с тем экземпляр типа n:m представляется двумя экземплярами типа 1:n, которые, в свою очередь, можно считать множествами экземпляров типа 1:1. Экземпляры типа связей не имеют уникальных идентификаторов. Тип связи 1:n напоминает тип набора модели данных КОДАСИЛ [16]. Семантика типа набора зависит от вида членства в наборе, которое специфицируется как OPTIONAL MANUAL, MANDATORY AUTOMATIC и др. Вид членства в наборе определяет семантику операций создания, удаления, модификации записи-члена (владельца) набора. Их семантика соответствует ссылочным ограничениям целостности, устанавливаемым видом членства в наборе.
Связи не имеют имени. Вместо этого именуются навигационные пути (traversal paths) для каждого направления навигации, например профессор преподает (teaches) совокупность разделов курсов, инверсное направление определяется тем, что разделы курсов преподаются (is_taught_by) профессорами. Эти имена объявляются в определениях интерфейсов, соответствующих типам, участвующим в связи:
interface Professor { ...
teaches: Set<Section> inverse Section::is_taught_by
}
и
interface Section { ... is_taught_by: Professor inverse Professor::teaches
}
Для типа связи 1-n определены следующие операции:
create(o1:Denotable_Object, s:Set<Denotable_Object>);
delete ();
add_one_to_one (o1:Denotable_Object, o2:Denotable_Object);
remove_one_to_one (o1:Denotable_Object, o2:Denotable_Object);
traverse (from:Denotable_Object) -> s: Set<Denotable_Object>.
С бурным развитием Интернет возникла потребность в удобном универсальном формате представления структурированных данных, не зависимых от аппаратно-программных платформ. Большая часть информации на заре развития WWW хранилась в HTML-документах. Формат HTML позволяет хорошо отображать информацию, но собственно для хранения структурированной информации он не предназначен.
Современная Интернет-инфраструктура представляет собой множество сайтов (узлов WWW), связанных каналами связи различной пропускной способности. Программное обеспечение крайне разнородно - начиная от различных серверных операционных систем и кончая разнородным клиентским интернет-ПО - броузерами. Тем не менее потребность в универсальных форматах представления структурированных данных позволила консорциуму W3C в феврале 1998 года принять стандарт, который был принят всеми ведущими разработчиками ПО: eXtensible Markup Language (XML 1998).
XML является подмножеством языка SGML (ISO 8879). Он определяет класс объектов, называемых XML-документами, и частично - поведение программ, которые работают с ними.
Структурными элементами XML являются:
- Документы
- Элементы
- Сущности
- Тело элемента
- Атрибуты элемента
- Значения атрибутов элемента
Структура документа задается в DTD - Document Type Definition. DTD является неотъемлемой частью стандарта XML. В DTD задаются правила, которым должны удовлетворять XML-документы данного типа, в том числе набор допустимых элементов, допустимость на вложения элементов в другие элементы, наличие и обязательность атрибутов у элементов.
Документ может быть правильно сформированным (well-formed), то есть синтаксически корректным, но при этом не быть валидным, т.е. не удовлетворять соответствующему DTD-описанию.
Структурно XML-документ представляет собой дерево, в корне которого всегда находится т.н. root (корневой элемент), содержащий вложенные элементы. Root не имеет имени, в отличие от элементов, в него вложенных. Каждый элемент имеет определенный тип, задаваемый в DTD.
Синтаксически элемент имеет тэг начала и тэг конца, за исключением пустых элементов, которые являются единым тэгом. Пустыми называются элементы, не имеющие вложенных элементов и тела. Пример непустого элемента с вложенными подэлементами:
<book>
<title>
Война и мир
</title>
<autor>
Лев Толстой
</autor>
</book>
В DTD определяется состав элемента, т.е. набор возможных типов элементов, которые могут входить в состав данного; также задается порядок следования и ограничения на количество вложенных элементов.
Элементы могут иметь атрибуты. Список атрибутов к данному типу элемента, обязательность и значения атрибутов по умолчанию также определяются DTD. Пример пустого элемента с атрибутами:
<book title="Война и мир" autor="Лев Толстой" />
Значение атрибута в приведенном примере - строковое значение. Стандартом в настоящее время не определена возможность задавать тип атрибута, например, числовой, дата, логический и т.д., хотя работы в этом направлении со стороны XML-сообщества ведутся. Атрибуты могут иметь тип идентификатора (id), а также ссылочный тип (idref). Такие атрибуты позволяют расширять дерево XML-документа до графа. Значение idref-атрибута обязательно должно иметь соответствующее значение id-атрибута в элементах текущего XML-документа.
DTD, помимо логической схемы документа (элементы, атрибуты), может определять и физическую структуру. Для этого введено понятие сущности. Под сущностью в XML понимается некий поименованный фрагмент XML-кода. Название сущности в определенном синтаксическом контексте эквивалентно подстановке фрагмента, связанного в DTD с именем сущности.
Схемы данных (Schemas) являются альтернативным способом создания правил построения XML-документов. По сравнению с DTD, схемы обладают более мощными средствами для определения сложных структур данных, обеспечивают более понятный способ описания грамматики языка, способны легко модернизироваться и расширяться. Безусловным достоинством схем является также то, что они позволяют описывать правила для XML- документа средствами самого же XML.
Однако это не означает, что схемы могут полностью заменить DTD- описания - этот способ определения грамматики языка используется сейчас практическими всеми верифицирующими анализаторами XML и, более того, сами схемы, как обычные XML- элементы, тоже описываются DTD. Но серьезные возможности нового языка и его относительная простота, безусловно, дают основания утверждать, что будущий стандарт найдет широкое применение в качестве удобного и эффективного средства проверки корректности составления документов.
В настоящее время в W3 консорциуме идет работа над первой спецификацией схем XML, рабочий ее вариант доступен на сервере W3C (XML-Schema 1999).
Пространства имен (namespaces) явились закономерным дополнением XML после того, как стало ясно, что набор элементов (тэгов) не может быть единым и универсальным для всех XML-приложений. Суть этого дополнения в том, что приложение, интерпретирующее XML-данные, может удостовериться в том, что данный документ использует именно те элементы схемы и именно в таком контексте, как это предусмотрено в этом приложении.
Иными словами, каждое применение (расширение) XML работает в своем пространстве имен, и, хотя названия элементов в разных пространствах могут совпадать, явная привязка элементов к определенному пространству имен однозначно определяет смысл данного элемента для XML-парсеров, приложений и пользователей.
Синтаксически namespaces представляют собой дополнения в названиях элементов XML-документа (префиксы), заранее объявленные в этом же документе с привязкой к определенному URI (универсальному идентификатору ресурса).
Ссылкой в стандарте XLink (XLink 1998) называется выраженная явно связь между двумя и более объектами данных или частями этих объектов. С понятием ссылки тесно связано понятие локатора, т.е. данных, однозначно идентифицирующих ресурс. Локатор является частью ссылки. Ресурс в данном контексте означает адресуемую порцию информации либо некоторый сервис, который также определяется адресом (локатором).
Со ссылкой связаны:
- один или несколько локаторов, идентифицирующих ресурсы, участвующие в ссылке
- семантика ссылки
- семантика ресурсов
В семантике ссылки определяется ее характер (локальная или внешняя), а также роль. Характер и роль задаются с помощью атрибутов. Под локальным ресурсом понимается информация, представленная в том же документе, что и ссылка. Роль ссылки - информация, необходимая для идентификации значения ссылки для программного обеспечения, работающего с данным XML-документом.
Изначально XML не предназначен для непосредственного отображения информации, как HTML. Для экранного представления XML-документов был создан стандарт XSL (eXtensible Style Language) (XSL 1998). Хотя первоначально XSL проектировался только как язык описания правил представления XML-деревьев в Web-броузерах, сейчас этот стандарт развился в довольно мощное средство поиска и трансформации XML-деревьев.
Составной частью XSL является язык XQL, позволяющий проводить поиск по XML-деревьям. Образцы, удовлетворяющие шаблону XQL, далее преобразуются в выходную структуру, получаемую из исходной посредством XSL-правил.
На рис. 1.4.3-1 приведена схема стандартов, которые основаны на XML либо связаны с ним. Среди них - язык описания математических формул MathML (MathML 1999), язык векторной графики VML (VML 1998), ранее рассмотренный RDF, и многие другие.
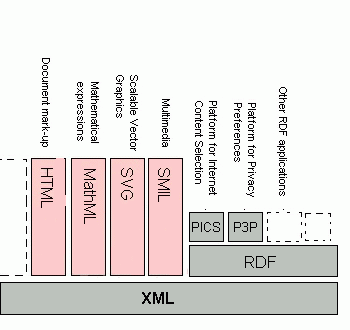
Рис. 1.4.3-1 Основанные на XML стандарты
Данный раздел содержит описание некоторых формальных языков запросов к структурированным источникам данных. Сначала дан сравнительный анализ этих языков, затем каждый из них рассматривается в отдельности, более подробно. В число рассматриваемых далее языков вошли следующие: SQL, OQL, XLS/XQL, XML-QL, RDF Query.
Можно сказать, что все формальные языки были созданы с целью унификации доступа к СИД различных производителей. В СУБД создание языка SQL ознаменовало качественный скачок рынка реляционных СУБД: разработчики СУБД стали следовать стандарту отрасли де-факто, а затем язык был закреплен в качестве официального стандарта. Все это позволило делать приложения, совместимые со многими СУБД.
Характеристики типов целевых СИД отражают различия в целях создания соответствующих языков запросов. Так, более строгие SQL и OQL были созданы для использования в коммерческих приложениях, использующих реляционные и объектные СУБД. Возвращаемые элементы (значения, кортежи и объекты) обычно используются в приложениях непосредственно в структурах данных, что во многом способствует интеграции этих языков в различные языки программирования (например, SQL - в Xbase, PL и PowerScript, OQL - в C++, Java и SmallTalk).
В Интернет-ориентированных языках запросов цели создания более разнообразны. Так, XSL первоначально был создан для визуального отображения XML-документов, структура шаблонов proposal-версии была очень схожа с аналогичной структурой в XML-QL (XSL Proposal 1997). Позднее разработчики XSL стали использовать для навигации по структуре документа язык XQL, а сам язык XSL в последнее время стал позиционироваться как универсальный язык поиска и трансформации XML-данных, наряду с первоначально заявленным предназначением (Bosworth 1998). Аналогичные цели (запросы к XML-ресурсам) преследует и XML-QL. RDF Query - это язык поиска ресурсов по их RDF-описанию. Его применение - различные поисковые машины.
Структура языков запросов базируется на общей структуре запроса как такового. В общем случае в запросе к СИД есть несколько частей:
- "Источник"
- "Дано"
- "Получить"
- "Упорядочить"
- "Группировать"
Эта часть запроса показывает, к какому СИД и к какой его части относится запрос. Для SQL эта часть запроса заключена после обязательного ключевого слова from, при этом указываются таблицы, из которых будет получен результат с возможной их связкой с помощью операторов Join. В RDF Query - с помощью элемента <from> указывается набор ресурсов, где будет осуществлен поиск. В языке XSL-XQL источник задан неявно, практически всегда это - текущий документ.
В OQL, а также в некоторых диалектах SQL допустимо указывать в качестве источника другой запрос. То же верно и для RDF Query.
В данной части запроса задается условие, которому должны удовлетворять запрашиваемые элементы СИД, будь то записи для SQL, объекты в OQL, или узлы дерева в XSL-XQL. Условия могут задаваться булевскими выражениями, допускаются логические операторы AND, OR, NOT. SQL допускает в качестве условий операторы IN и EXISTS, которые определяют истинность нахождения некоторого значения во вложенном запросе для IN и истинность существования хотя бы одной записи во вложенном запросе с заданными условиями для EXISTS. OQL и RDF Query имеет операторы-квантификаторы EXISTS и FORALL, которые имеют то же значение, что и в математической логике.
В этой части задается ограничение/трансформация полученных элементов. Для SQL после ключевого слова SELECT идет перечисление полей таблиц и/или выражений над ними. В OQL, помимо выражений и объектов, в рассматриваемой части запроса могут участвовать аксессоры. В XSL задействован механизм трансформации деревьев, который преобразует исходное дерево документа в новое, задаваемое правилами трансформации. RDF Query позволяет получить ресурсы, удовлетворяющие заданным условиям, либо значения агрегатной функции (например, количество ресурсов).
Языки SQL и OQL имеют ключевое слово ORDER, которое задает порядок сортировки получаемых результатов. Аналогичный элемент имеет и RDF Query.
Каждый тип СИД имеет свои типы элементов (см. раздел "Типы СИД"), и характеристики этих элементов существенно влияют на способ их обработки языками запросов и на структуру языка в целом.
В SQL первичными являются элементы таблица, запись и поле. Строгость реляционной алгебры накладывает отпечаток на пространство допустимых форм запросов на этом языке.
В OQL первичными элементами выступает объект и его атрибуты. Объектно-ориентированная парадигма математически менее формализована, чем реляционная, и это отразилось на структуре OQL.
Для Интернет-ориентированных типов СИД структурными элементами выступают единицы, более аморфные с точки зрения внутренней структуры - элементы документа представляются в виде узлов дерева или графа. Соответственно, поисковые шаблоны для этих языков допускают поиск не только по значениям определенных атрибутов, но и по наличию таких атрибутов в элементах, а также по наличию самих элементов:
Примеры шаблонов в XQL:
./author - найти все элементы author в текущем контексте поиска.
book[/bookstore/@specialty = @style] - все книги, у которых значение атрибута style равно значению атрибута specialty элемента bookstore в корневом узле документа.
Пример условия в RDF Query:
<rdfq:Select>
<rdfq:Condition>
<rdfq:equals>
<rdfq:Property
name="Project"
/>
<rdf:String>WebTechnologies</rdf:String>
</rdfq:equals>
</rdfq:Condition>
</rfq:Select>
В последнем примере ищутся документы, удовлетворяющие следующим условиям: свойство Project должно равняться строковому значению "WebTechnologies".
Рассмотрим теперь отдельно каждый из выбранных языков.
Данный язык запросов - самый распространенный, и, пожалуй, наиболее формализованный язык запросов к базам данных. Он был создан IBM в качестве попытки создания универсального языка запросов к реляционным базам данных, с которым могли бы работать пользователи баз данных. Эта ориентированность на пользователя во многом повлияла на синтаксис языка (примечательно, что в ранней версии названия фигурировало слово English, от этого в качестве рудимента остался лишний звук при произношении аббревиатуры - SQL читается как se-ku-el).
Простые запросы на SQL человеком обычно читаются достаточно легко. Так, SQL-запрос
select name, salary
from Personnel
where post like "%engineer%"
соответствует ЕЯ-запросу "имя и зарплата инженеров". SQL, помимо ключевых слов select, from, where, может иметь также операторы сортировки (order by) и группировки результата (group by). Несмотря на серьезные усилия по стандартизации (первый официальный стандарт был принят в 1989 году, последним вышедшим стандартом является SQL-92, готовится к принятию стандарт с условным названием SQL-3, который в качестве подмножества будет включать в себя OQL), существует множество диалектов этого языка. Практически каждая коммерческая СУБД имеет некоторые особенности, несовместимые с конкурирующими версиями SQL. Чаще всего это касается встроенных (built-in) функций и использования вложенных запросов.
Для связывания нескольких таблиц в одном запросе необходимо указать их в части from, и использовать операторы равенства в части where, либо использовать оператор join (соединения) в части from. Стандарт SQL-89 допускает несколько типов join - внешний, внутренний. В стандарте SQL-92 появляется еще и естественные, объединительные и кросс-соединительные join.
Как и в реляционной алгебре, операторы объединения (UNION), пересечения (INTERSECT) и разности (EXCEPT) применимы к двум таблицам, которые должны быть объединительно-совместимы. Этот термин в SQL имеет несколько отличающееся от реляционной алгебры значение. Две таблицы объединительно-совместимы, если в них одинаковое число столбцов и соответствующие столбцы имеют совместимые типы данных, то есть такие типы, которые могут быть легко преобразованы друг в друга. Наприме, два числовых типа не обязательно должны совпадать, но они должны преобразовываться друг в друга.
Необходимо заметить, что в стандарт SQL, помимо собственно оператора запроса select, входят еще и команды определения данных, которые образуют язык определения данных (Data Definition Language - DDL). Так, операторы update, insert, delete в некоторых СУБД в качестве условной части могут использовать SQL-запрос. Все эти операции не вошли в данный обзор, поскольку приводят к изменениям в базе данных, что не входит в тему запросов к СИД.
Первоначальная версия языка объектных запросов (Object Query Language - OQL) определена относительно независимо от языка SQL: язык объектных запросов обладает более богатой семантикой. Так, OQL включает манипулирование данными произвольной сложности, вызов методов, полиморфизм типов на основе позднего связывания, введение выражений путей в композиционной структуре объектов, работу с произвольными объектами (независимо от их времени жизни). Впоследствии принято решение принять в OQL синтаксис SQL-92, не уменьшая его (OQL) семантической мощности. Здесь рассматривается именно эта, более поздняя, редакция языка OQL.
Синтаксически OQL является расширением языка SQL. В частности, любое предложение select SQL, применимое к таблицам, используется без изменений над коллекциями объектов ODMG, состояние которых представляют строки таблиц. Вместе с тем OQL опирается на объектную модель ODMG-93 и является типизированным языком запросов. Результатом запроса на OQL могут быть одиночные значения (изменчивые или неизменчивые) любых типов, представимых на ODL, либо коллекции таких значений. OQL является функциональным языком в том смысле, что допускается произвольная композиция операторов, если только их операнды имеют требуемые типы. Поскольку результат любого запроса имеет тип, соответствующий ODL, к нему можно снова применить запрос. OQL - самостоятельный язык, который может использоваться динамически. Вместе с тем запросы на OQL могут вызываться из программы на любом языке программирования, для которого определено связывание с ODMG-93. В свою очередь из запросов на OQL могут вызываться программы, написанные на таких языках программирования. Запросы могут реализовать изменения базы данных, если они вызывают операции на объектах, явно или неявно реализующие такие изменения.
В базу данных можно войти, используя имя объекта, или, в более общем случае, как только становится известным некоторый объект (например в результате выполнения программы на C++). После этого можно осуществить "навигацию" в базе данных для достижения требуемых данных. Например, пусть p-объект типа Person, и требуется определить название города, в котором живет супруг(а) этого человека. Для навигации используется точечная нотация, определяющая путь:
p.spouse.address.city.name
Этот запрос начинается с p, определяет супруга этого лица (которого снова представляет объект типа Person), забирается внутрь атрибута-структуры Address для определения объекта типа City, имя которого затем остается определить. Существенно, что компонентами пути могут быть операции объектов с параметрами или без них, если результатом операции является требуемый объект:
Doe.apply_course
("Math", Turing).number
Этот запрос применяет операцию apply_course к объекту Doe типа Student. Операция требует два параметра - строку и объект типа Professor. Операция возвращает объект типа Course, а запрос определяет номер курса.
Выражения путей достаточны для проникновения внутрь сложных объектов и прослеживания связей 1:1. В случае связей 1:n требуется применение фраз select-from-where SQL для определения коллекций объектов, связанных с объектом p. Например, множество имен детей p образуется посредством запроса:
select distinct c.name from p.children c
Фраза where может содержать произвольный предикат, служащий для отбора требуемых данных. Запросы, подразумевающие соединение (join) коллекций, формулируются обычно. Например, найти объекты типа Person, имена которых совпадают с названиями цветов:
select p from Person.p, Flowers f where p.name = f.name
Существенной для объектной ориентации является возможность манипулирования полиморфными коллекциями, что, благодаря позднему связыванию, позволяет выполнять родовые операции над элементами таких коллекций. Пусть множество Persons содержит объекты типа Person, Employee, Student. Запросы к Persons имеют дело с объектами трех типов. Пусть activities - метод, который имеет различные представления в каждом из трех типов объектов. В зависимости от типа текущего объекта вызывается соответствующий метод activities:
select p.activities from Persons.p
Можно явно задать тип объектов, которые следует рассматривать в полиморфной коллекции. Например, если известно, что только студенты проводят свое время, изучая определенные курсы, можно извлечь таковых из множества Persons посредством явной типизации запроса:
select (Student)p.grade from Persons p where"course of study" in p.activities
Операторы языка OQL допускают произвольную композицию, единственным ограничением для которой является правильная типизация операндов и результатов операторов. К подобным операторам языка относятся: множественные операторы (union, intersect, except), кванторы (for all, exists), операторы sort и group by, операторы аггрегации (count, sum, min, max, avg). В отличие от языка SQL, конструкции OQL являются полностью ортогональными. Там, где синтаксис языка SQL не является чисто функциональным, OQL принимает эту трактовку SQL как допустимый синтаксический вариант.
Композиция операторов показана на примере сложного запроса: определить название улицы, на которой живут сотрудники, имеющие в среднем наименьшую зарплату в сравнении с сотрудниками, живущими на других улицах.
first(select street, average_salary: avg(select e.salary from partition) from(select (Employee) p from Persons p where "has a job" in p.activities) as e group by street: e.address.street order by average_salary).street
Оператор group by расщепляет совокупность Employee на подразделы (partitions) в соответствии с заданным критерием (в нашем случае по имени улицы, на которой живет сотрудник). Оператор order by приводит к образованию списка структур типа List<struc(street:string, average_salary: float)>, упорядоченного по возрастанию значений средней зарплаты. Наименьшая зарплата соответствует первой структуре в списке.
Язык XSL (extensible stylesheet language) использует в качестве языка задания шаблонов для поиска язык XQL (XML query language).
Общую идею XSL можно выразить следующим образом: это язык трансформации XML-документов со средствами задания семантики визуального форматирования. Язык состоит из двух частей:
- Язык трансформации XML-документов.
- XML-словарь для задания семантики форматирования.
Предшественником XSL является язык стилевых таблиц CSS. CSS определяет стилевое оформление HTML-документов - он расширяет возможности их форматирования и позволяет отделить структуру HTML-документа от его стилевого оформления. XSL же изначально был разработан для форматирования XML-документов, и он имеет XML-синтаксис. В части форматирования от CSS его отличает более абстрактная модель объектов форматирования.
1.5.6.1 Шаблоны форматирования
Несмотря на более специфические цели создания, XSL пригоден для более общей задачи - для трансформации XML-документов на основе шаблонов. XSL строится с помощью стилевых таблиц (stylesheets). Стилевая таблица - это упорядоченный список шаблонов форматирования (templates). Шаблон состоит из двух основных частей - из поискового шаблона, который служит для навигации по исходному документу, и шаблона для построения выходного документа (constructing templates), в котором задаются создаваемые элементы. В создаваемые элементы допускается включать те элементы исходного документа, на которые "сработало" данное правило.
Шаблон для построения выходного фрагмента может содержать как элементы форматирования, определяемые данным стандартом в XML-словаре Formatting Objects (префикс таких элементов - fo), так и другие произвольные элементы:
<xsl:template match="chapter/title">
<fo:rule-graphic/>
<fo:block space-before="2pt">
<xsl:text>Chapter </xsl:text>
<xsl:number/>
<xsl:text>: </xsl:text>
<xsl:apply-templates/>
</fo:block>
<fo:rule-graphic/>
</xsl:template>
В данном примере из элемента title, вложенного в элемент chapter в исходном документе, формируется фрагмент выходного документа, который содержит текст "Chapter <номер> : <title>", то есть создается заголовок главы. Кроме того, в шаблоне задается смещение заголовка на два пункта. Заметим, что создаваемый фрагмент содержит и сам исходный элемент <title>.
В документе, описывающем XQL [XQL Proposal], говорится, что "он является естественным расширением синтаксиса XSL-шаблонов". XQL является нотацией для адресации и фильтрации элементов и текста в XML-документах.
Базовый синтаксис XQL имитирует синтаксис навигации по директориям в URI (Universal Resource Identificator) [URI], но вместо навигации по дереву директорий идет навигация по XML-документу. Например:
Найти все элементы author в текущем контексте:
./author
Это эквивалентно следующему примеру:
author
Найти корневой элемент (bookstore) текущего документа:
/bookstore
Найти все элементы author в документе, безотносительно от текущего контекста и расположения элементов:
//author
Помимо поиска элементов данного типа, XQL позволяет искать элементы с определенными атрибутами, а также с определенными значениями атрибутов:
Найти атрибут exchange в элементах price в текущем контексте:
price/@exchange
Атрибут from элемента degree, не равный 'Harvard':
degree[@from != 'Harvard']
Возможен также поиск по тексту внутри элементов:
Найти всех авторов с именем 'Bob' (имя в документе задается как текст элемента author):
author[text() = 'Bob']
XQL также позволяет адресоваться к элементам в коллекции по индексу. Так, в следующем XML-дереве:
<x>
<y/>
<y/>
</x>
<x>
<y/>
<y/>
</x>
следующее выражение возвратит первый элемент y из каждого элемента x:
x/y[0]
следующий - возвратит первый y из множества y-ов внутри x-ов:
(x/y)[0]
этот пример возвратит первый y из первого x:
x[0]/y[0]
Кроме того, можно получить индекс элемента с помощью метода index():
x/y[index() = 0]
(возвращает первый y из каждого x).
Несмотря на достаточную гибкость при форматировании XML-документов, XSL имеет ряд ограничений (Bosworth 1998):
- Не поддерживаются выражения. Например, невозможно задать следующее ограничение: @price * @quantity > 50 или явно получить значение данного выражения.
- Нет поддержки аггрегации или группировки (Group-By).
- Невозможно связать два узла по значению.
- Есть только ограниченная поддержка явных связей и атрибутов IDREF в исходном XML-документе.
- Нет формального механизма запрашивания во множестве отдельных XML-документов.
- Не поддерживаются графы. XSL не может создавать настоящие графы стандартным механизмом, поскольку тогда бы в различных местах правила создания (construction rules) создавали одни и те же элементы.
- Отсутствует удобный способ делать запросы с параметрами (например, как в SQL).
Там же предлагается ряд расширений для данного стандарта.
Этот язык является альтернативой XSL. Но в отличие от XSL, он не предназначен для форматирования документов. Как указано в стандарте, XML QL "подобно SQL, имеет SELECT-WHERE структуру, и заимствует особенности языков запросов, разработанных в последнее время сообществом исследования в области баз данных для слабоструктурированных данных" (XML-QL).
XML-QL использует шаблоны элементов для поиска данных в XML-документе. Следующий пример возвращает всех авторов, а также названия книг издательства Addison-Wesley в документе с адресом www.a.b.c/bib.xml:
WHERE <book>
<publisher><name>Addison-Wesley</name></publisher>
<title> $t</title>
<author> $a</author>
</book> IN "www.a.b.c/bib.xml"
CONSTRUCT <result>
<author> $a</>
<title> $t</>
</>
В языке есть возможность группирования с помощью вложенных запросов. В предыдущем запросе различные авторы одной и той же книги появлялись в различных выходных элементах <result>. Для того, чтобы сгруппировать в результате авторов по названию книг, может быть построен следующий запрос:
WHERE <book > $p</> IN "www.a.b.c/bib.xml",
<title > $t</>,
<publisher><name>Addison-Wesley</>> IN $p
CONSTRUCT <result>
<title> $t </>
WHERE <author> $a </> IN $p
CONSTRUCT <author> $a</>
</>
Подобно SQL, XML-QL позволяет делать соединения (joins) сопоставлением двух или более элементов, содержащих одинаковые значения. Например, следующий запрос возвращает все статьи, имеющие по крайней мере одного автора, который написал книгу с 1995 года:
WHERE <article>
<author>
<firstname> $f </> // firstname $f
<lastname> $l </> // lastname $l
</>
</> CONTENT_AS $a IN "www.a.b.c/bib.xml"
<book year=$y>
<author>
<firstname> $f </> // join on same firstname $f
<lastname> $l </> // join on same lastname $l
</>
</> IN "www.a.b.c/bib.xml",
y > 1995
CONSTRUCT <article> $a </>
В одном XML-QL-запросе можно комбинировать данные из нескольких XML-источников (документов), также, как и в SQL, возможна сортировка результата. В стандарт входит также возможность определения функций с параметрами.
Существенным недостатком данного языка запросов можно назвать отсутствие возможности работы со значениями атрибутов элементов - возможно искать элементы только по их содержимому.
Авторы RDF Query определяют его как декларативный язык запросов для RDF (Malhotra, Sundaresan 1998). В отличие от уже рассмотренных языков запросов, RDF Query возвращает в качестве результата запроса множество ресурсов, при этом внутренняя структура ресурса никак не трансформируется. Результирующее множество ресурсов всегда является подмножеством исходного множества и может быть пустым. Результирующее множество может быть источником для другого запроса.
В запросе можно указывать наличие определенного атрибута в ресурсе, а также некоторые условия. В условия могут входить равенства и другие операторы сравнения, логические операторы. Для навигации по XML-элементам используются пути (path), как в следующем примере:
<rdfq:rdfquery>
<rdfq:From
eachResource="http://www.research.ibm.com/people/neel"/>
<rdfq:Select>
<rdfq:Condition>
<rdfq:not>
<rdfq:equal>
<rdfq:Property
path="ResearchPapers/Conference/Venue/Country"/>
<rdf:String>U.S.A.</rdf:String>
</rdfq:equal>
</rdfq:not>
</rdfq:Condition>
</rdfq:Select>
</rdfq:rdfquery>
Такое задание путей схоже с аксессорами в OQL, а также с шаблонами в XQL.
Выше уже говорилось об отличии RDF Query от других языков запросов к XML-документам - он не преобразует структуру документа. Однако в языке имеется возможность извлекать некоторые элементы из ресурсов и делать из этих элементов "доверенные" ресурсы. Эта возможность аналогична указыванию в SQL выдаваемых в запросе полей после ключевого слова select. Кроме этого, возможно агрегирование, а именно вычисление количества ресурсов с помощью атрибута count. Так же, как и в SQL, здесь возможна группировка. Под группировкой здесь понимается помещение ресурсов в подмножества, группировка производится по значениям указанных элементов. Еще одна аналогия с SQL - возможность сортировки ресурсов по значениям элементов.
Источник: (Компьютерный диалог)
Дополнительно
Дисертация Владислава Жигалова
http://www.aha.ru/~zhigalov/science/disser.zip - Word'97 (zip - 336k)