Разделы
Счетчики
Модели памяти, основанные на математической операции свертки (Convolution-based memory models)[1].
Общая идея
CBMM (Convolution-based memory models) - это класс математических моделей, основанных на представлении о распределенном хранении данных в нервной системе. Все модели данного типа используют операцию свертки в схемах формирования энграммы (отпечатка в памяти).
Запоминаемая информация обычно представляется в виде бинарного или цифрового вектора (pattern) и сохраняется в виде множества взаимосвязей этих векторов.
Свойства и математическое описание моделей очень похожи на свойства и математическое описание световой голограммы, поэтому они иногда называются голографическими моделями памяти. Например, так же как и в голограмме, в модели возможна реконструкция (хотя и в зашумленном виде) данных по зашумленному образцу или только по части образца, что является следствием распределенного хранения информации.
Процесс формирования энграммы описывается двумя операциями: суперпозицией и связыванием (ассоциированием). Для образцов в виде числового вектора суперпозицией является обычная операция сложения. В качестве операции связывания (ассоциирования) используется свертка. Для n мерных векторов она равна:
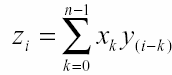
Обычно используется сокращенная запись этого уравнения:
![]()
В моделях могут использоваться различные варианты расчета свертки. Например, "кольцевая" свертка, которая может быть представлена как "компрессия" векторного произведения, полученная суммированием соответствующих элементов (см. след. рис.)
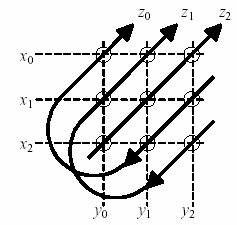
Результатом кольцевой свертки является вектор той же размерности n, что и исходные векторы X, Y.
Важным свойством свертки является сохранение подобия. Например, если red подобно pink то redДsquare подобно pinkДsquare в той же степени. Степень подобия может быть выражена численно, по формуле:
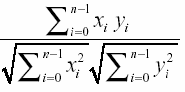
Свертка легко может быть декодирована с помощью обратной операции свертки:
red-1ДredДcircle = circle.
При этом используются методы приближенного вычисление, так как точная операция численно нестабильна при наличии шума.
Таким же способом возможно декодирование суперпозиции нескольких ассоциаций. Например, суперпозиция (redДcircle)+(blueДsquare) может быть декодирована так:
Blue-1Д ((red Дcircle)+(blueДsquare))= (blue-1Д redДcircle) + (blue-1Д blueДsquare)» square.
(blue-1Д red Д circle) - не будет подобно ни одному из элементов blue, red, circle, square и может рассматриваться как шум, а значение (blue-1Д blueДsquare) равно зашумленной версии square.
При многократной суперпозиции увеличивается зашумление данных (эффект интерференции). Увеличение размерности вектора, представляющего данные, снижает степень зашумленности при декодировании.
Модель TODAM (Theory of Distributed Associative Memory) [2]
Модель создана для описания экспериментальных результатов, полученных в опытах по исследованию запоминания человеком списка ассоциативных пар слов. Эксперименты обычно проводят следующим образом. Испытуемого просят запомнить список пар слов, например: "корова-лошадь, собака-кошка, ручка-карандаш". Затем ему задают вопросы такого типа: "Было ли в списке слово "машина"?" (тест на распознавание), "Какое слово было в паре со словом "кошка"?" (тест на вспоминание по ассоциации). В экспериментах варьируются такие параметры как: длина списка, степень известности слов, степень их подобия (однородность) и положение слов в списке. Данные о количестве и типе ошибок, возникающих при ответах, позволяет изучить и понять некоторые свойства человеческой памяти.
Модель формирования энграммы в модели TODAM описывается формулой:
Tj= a T j-1+g1 x j+g2 y j +g3 x j Дy j
Где Tj – вектор, представляющий энграмму списка из j ассоциативных пар.
a, g1, g2, g3 –константы модели, имеющие значение в диапазоне от 0 до 1.
Xj, Yj – векторы, отображающие ассоциированную пару слов из списка.
В численных экспериментах считается, что образец распознаваем по энграмме, если скалярное произведение энграммы и образца больше некоторого порога шума. Образец X из пары (X,Y) считается вспомненным ассоциативно, если операция x-1ДT – позволяет реконструировать значение y.
Модель TODAM позволяет воспроизводить следующие известные в психологии (полученные экспериментально) закономерности:
- Эффективность запоминания снижается при увеличении длины списка.
- Ассоциативное запоминание симметрично. Т.е. если в списке есть пара (X,Y), то воспроизведение X по Y тем лучше, чем лучше воспроизведение Y по X.
- Эффект новизны (recency effect) – слова из конца списка запоминаются лучше чем из середины. Этот эффект легко можно обнаружить в модели, если расписать ее более подробно. Возьмем для примера три пары слов (a,b), (c,d), (e,f). Для них получаем:
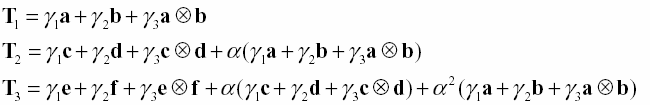
Отсюда видно, что забывание слов пропорционально aj-1.
Следует заметить, что в реальных экспериментах обнаруживается также и эффект первенства (primacy effect) – слова из начала списка запоминаются лучше чем из середины. Но данная модель не описывает этот эффект (для его воспроизведения необходима модель, включающая описание взаимодействия кратковременной и долговременной памяти).
- Ассоциативное вспоминание более мощно, чем распознавание. Не опознанный образец, может быть вспомнен по ассоциации.
Модель CHARM ("Composite Holographic Associative Recall Model") [3]
Модель ориентирована на описание эффекта однородности списка запоминаемых ассоциативных пар. Формирование энграммы описывается формулой:
Ti = еx i Дy i.
Т.е. это сокращенная версия TODAM, в которой сохраняется только ассоциативная информация.
Одним из эффектов, воспроизводимой моделью, является снижение способности к запоминанию списков с похожими образцами. В реальных экспериментах это проявляется, например, в том, что список, состоящий только из известных имен, запоминается хуже, чем список, состоящий из слов на совершенно разные темы. Более того, в модели, как и в реальных экспериментах, наиболее часто наблюдался один и тот же тип ошибки – ошибочное вспоминание по ассоциации слова, имеющегося в списке и похожего на требуемое.
Модель HRRs (Holographic Reduced Representations)[4]
Это модель, способная оперировать рекурсивной информационной структурой. Она необходима для решения таких когнитивных задач, как, например пониманием естественного языка.
В HRRs модели энграмма фразы "политики говорят неправду" выглядит так:
ЭНГговорят=ПОЛИТИКИ+ГОВОРЯТ+НЕПРАВДУ+
+ГОВОРЯТконтейнерДПОЛИТИКИ+ ГОВОРЯТсодержимоеДНЕПРАВДУ
В формуле большими буквами обозначены векторы, представляющие слова из фразы, мелким курсивом –структура с точки зрения которой рассматривается слово.
Если нам известна энграмма ЭНГговорят и значение контейнера ГОВОРЯТконтейнер, то мы можем "вытянуть" содержимое контейнера
ГОВОРЯТ-1контейнерДЭНГговорят » ПОЛИТИКИ
Энграмма ЭНТговорят является редуцированным представлением фразы “политики говорят неправду”, которая также может выступать в роле содержимого для контейнера более высокого порядка. Например, фраза “я думаю, политики говорят неправду” может быть представлена так:
ЭНГдумаю=Я+ДУМАЮ+ЭНГговорят+ ДУМАЮконтейнерДЯ+
+ДУМАЮсодержимоеДЭНГговорят
Энграмма более высокого уровня ЭНГдумаю может быть декодирована:
ДУМАЮ-1контейнерДЭНГдумаю » ЭНГговорят
CBMM модели в нейронных сетях
Математические операции, используемые в CBMM моделях, могут быть воспроизведены в "sigma-pi" нейронных сетях. Например, так будет выглядеть нейронная сеть, вычисляющая кольцевую свертку двух векторов:
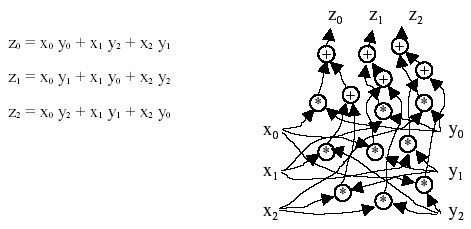
Может показаться, что реализация таких операций слишком сложна и требует слишком большой точности организации для биологических систем. Однако, в работах [5, 6] было показано, что "sigma-pi" нейронная сеть, осуществляющая суммирование произведений случайно выбранных элементов двух векторов, может выполнять операции кодирования и декодирования. Причем эти операции обладают теми же свойствами, что и операции свертки.
Литература
- ENCYCLOPEDIA OF COGNITIVE SCIENCE 2000 ©Macmillan Reference Ltd Article No 50
- Murdock, B. B. (1982). A theory for the storage and retrieval of item and associative information. Psychological Review 89 (6), 316–338.
- Metcalfe Eich, J. (1982). A composite holographic associative recall model.Psychological Review 89, 627–661.
- Plate, T. A. (1995). Holographic reduced representations. IEEE Transactions on Neural Networks 6 (3), 623–641.
- Plate, T. (2000). Randomly connected sigma-pi neurons can form associator networks. Network: Computation in Neural Systems 11 (4), 321–332.
- Plate, T. (2000). Structured operations with vector representations. Expert Systems: The International Journal of Knowledge Engineering and Neural Networks 17 (1), 29–40. Special Issue on Connectionist Symbol Processing.